MySQL纯代码复习(上)
前言
本文章是用于总结尚硅谷MySQL教学视频的记录文章,主要用于复习,非商用
原视频连接:https://www.bilibili.com/video/BV1iq4y1u7vj/?p=21&spm_id_from=pageDriver&vd_source=c4ecde834521bad789baa9ee29af1f6c
https://www.bilibili.com/video/BV1iq4y1u7vj/?p=21&spm_id_from=pageDriver&vd_source=c4ecde834521bad789baa9ee29af1f6c
该文章记录视频中绝大部分的代码,其中会包夹一些个人表述,适合后续复习使用
本章的内容几乎是以查询为中心来学习,本文章是MySQL纯代码复习上,MySQL纯代码复习下会着重将MySQL的使用基础,因为毕竟是一个数据库语言,并非只有查询,也少不了增删改和创建存储等等复杂的过程!
本系列问章,查询和后续的增删改存储会各占一半的量(意义上的量)
文章所用案例表
这是所有数据表的代码,可以复制下来执行运行,来生成表,进行练习
/*
SQLyog Ultimate v12.08 (64 bit)
MySQL - 5.7.28-log : Database - atguigudb
*********************************************************************
*/
/*!40101 SET NAMES utf8 */;
/*!40101 SET SQL_MODE=''*/;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
CREATE DATABASE /*!32312 IF NOT EXISTS*/`atguigudb` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `atguigudb`;
/*Table structure for table `countries` */
DROP TABLE IF EXISTS `countries`;
CREATE TABLE `countries` (
`country_id` char(2) NOT NULL,
`country_name` varchar(40) DEFAULT NULL,
`region_id` int(11) DEFAULT NULL,
PRIMARY KEY (`country_id`),
KEY `countr_reg_fk` (`region_id`),
CONSTRAINT `countr_reg_fk` FOREIGN KEY (`region_id`) REFERENCES `regions` (`region_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `countries` */
insert into `countries`(`country_id`,`country_name`,`region_id`) values ('AR','Argentina',2),('AU','Australia',3),('BE','Belgium',1),('BR','Brazil',2),('CA','Canada',2),('CH','Switzerland',1),('CN','China',3),('DE','Germany',1),('DK','Denmark',1),('EG','Egypt',4),('FR','France',1),('HK','HongKong',3),('IL','Israel',4),('IN','India',3),('IT','Italy',1),('JP','Japan',3),('KW','Kuwait',4),('MX','Mexico',2),('NG','Nigeria',4),('NL','Netherlands',1),('SG','Singapore',3),('UK','United Kingdom',1),('US','United States of America',2),('ZM','Zambia',4),('ZW','Zimbabwe',4);
/*Table structure for table `departments` */
DROP TABLE IF EXISTS `departments`;
CREATE TABLE `departments` (
`department_id` int(4) NOT NULL DEFAULT '0',
`department_name` varchar(30) NOT NULL,
`manager_id` int(6) DEFAULT NULL,
`location_id` int(4) DEFAULT NULL,
PRIMARY KEY (`department_id`),
UNIQUE KEY `dept_id_pk` (`department_id`),
KEY `dept_loc_fk` (`location_id`),
KEY `dept_mgr_fk` (`manager_id`),
CONSTRAINT `dept_loc_fk` FOREIGN KEY (`location_id`) REFERENCES `locations` (`location_id`),
CONSTRAINT `dept_mgr_fk` FOREIGN KEY (`manager_id`) REFERENCES `employees` (`employee_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `departments` */
insert into `departments`(`department_id`,`department_name`,`manager_id`,`location_id`) values (10,'Administration',200,1700),(20,'Marketing',201,1800),(30,'Purchasing',114,1700),(40,'Human Resources',203,2400),(50,'Shipping',121,1500),(60,'IT',103,1400),(70,'Public Relations',204,2700),(80,'Sales',145,2500),(90,'Executive',100,1700),(100,'Finance',108,1700),(110,'Accounting',205,1700),(120,'Treasury',NULL,1700),(130,'Corporate Tax',NULL,1700),(140,'Control And Credit',NULL,1700),(150,'Shareholder Services',NULL,1700),(160,'Benefits',NULL,1700),(170,'Manufacturing',NULL,1700),(180,'Construction',NULL,1700),(190,'Contracting',NULL,1700),(200,'Operations',NULL,1700),(210,'IT Support',NULL,1700),(220,'NOC',NULL,1700),(230,'IT Helpdesk',NULL,1700),(240,'Government Sales',NULL,1700),(250,'Retail Sales',NULL,1700),(260,'Recruiting',NULL,1700),(270,'Payroll',NULL,1700);
/*Table structure for table `employees` */
DROP TABLE IF EXISTS `employees`;
CREATE TABLE `employees` (
`employee_id` int(6) NOT NULL DEFAULT '0',
`first_name` varchar(20) DEFAULT NULL,
`last_name` varchar(25) NOT NULL,
`email` varchar(25) NOT NULL,
`phone_number` varchar(20) DEFAULT NULL,
`hire_date` date NOT NULL,
`job_id` varchar(10) NOT NULL,
`salary` double(8,2) DEFAULT NULL,
`commission_pct` double(2,2) DEFAULT NULL,
`manager_id` int(6) DEFAULT NULL,
`department_id` int(4) DEFAULT NULL,
PRIMARY KEY (`employee_id`),
UNIQUE KEY `emp_email_uk` (`email`),
UNIQUE KEY `emp_emp_id_pk` (`employee_id`),
KEY `emp_dept_fk` (`department_id`),
KEY `emp_job_fk` (`job_id`),
KEY `emp_manager_fk` (`manager_id`),
CONSTRAINT `emp_dept_fk` FOREIGN KEY (`department_id`) REFERENCES `departments` (`department_id`),
CONSTRAINT `emp_job_fk` FOREIGN KEY (`job_id`) REFERENCES `jobs` (`job_id`),
CONSTRAINT `emp_manager_fk` FOREIGN KEY (`manager_id`) REFERENCES `employees` (`employee_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `employees` */
insert into `employees`(`employee_id`,`first_name`,`last_name`,`email`,`phone_number`,`hire_date`,`job_id`,`salary`,`commission_pct`,`manager_id`,`department_id`) values (100,'Steven','King','SKING','515.123.4567','1987-06-17','AD_PRES',24000.00,NULL,NULL,90),(101,'Neena','Kochhar','NKOCHHAR','515.123.4568','1989-09-21','AD_VP',17000.00,NULL,100,90),(102,'Lex','De Haan','LDEHAAN','515.123.4569','1993-01-13','AD_VP',17000.00,NULL,100,90),(103,'Alexander','Hunold','AHUNOLD','590.423.4567','1990-01-03','IT_PROG',9000.00,NULL,102,60),(104,'Bruce','Ernst','BERNST','590.423.4568','1991-05-21','IT_PROG',6000.00,NULL,103,60),(105,'David','Austin','DAUSTIN','590.423.4569','1997-06-25','IT_PROG',4800.00,NULL,103,60),(106,'Valli','Pataballa','VPATABAL','590.423.4560','1998-02-05','IT_PROG',4800.00,NULL,103,60),(107,'Diana','Lorentz','DLORENTZ','590.423.5567','1999-02-07','IT_PROG',4200.00,NULL,103,60),(108,'Nancy','Greenberg','NGREENBE','515.124.4569','1994-08-17','FI_MGR',12000.00,NULL,101,100),(109,'Daniel','Faviet','DFAVIET','515.124.4169','1994-08-16','FI_ACCOUNT',9000.00,NULL,108,100),(110,'John','Chen','JCHEN','515.124.4269','1997-09-28','FI_ACCOUNT',8200.00,NULL,108,100),(111,'Ismael','Sciarra','ISCIARRA','515.124.4369','1997-09-30','FI_ACCOUNT',7700.00,NULL,108,100),(112,'Jose Manuel','Urman','JMURMAN','515.124.4469','1998-03-07','FI_ACCOUNT',7800.00,NULL,108,100),(113,'Luis','Popp','LPOPP','515.124.4567','1999-12-07','FI_ACCOUNT',6900.00,NULL,108,100),(114,'Den','Raphaely','DRAPHEAL','515.127.4561','1994-12-07','PU_MAN',11000.00,NULL,100,30),(115,'Alexander','Khoo','AKHOO','515.127.4562','1995-05-18','PU_CLERK',3100.00,NULL,114,30),(116,'Shelli','Baida','SBAIDA','515.127.4563','1997-12-24','PU_CLERK',2900.00,NULL,114,30),(117,'Sigal','Tobias','STOBIAS','515.127.4564','1997-07-24','PU_CLERK',2800.00,NULL,114,30),(118,'Guy','Himuro','GHIMURO','515.127.4565','1998-11-15','PU_CLERK',2600.00,NULL,114,30),(119,'Karen','Colmenares','KCOLMENA','515.127.4566','1999-08-10','PU_CLERK',2500.00,NULL,114,30),(120,'Matthew','Weiss','MWEISS','650.123.1234','1996-07-18','ST_MAN',8000.00,NULL,100,50),(121,'Adam','Fripp','AFRIPP','650.123.2234','1997-04-10','ST_MAN',8200.00,NULL,100,50),(122,'Payam','Kaufling','PKAUFLIN','650.123.3234','1995-05-01','ST_MAN',7900.00,NULL,100,50),(123,'Shanta','Vollman','SVOLLMAN','650.123.4234','1997-10-10','ST_MAN',6500.00,NULL,100,50),(124,'Kevin','Mourgos','KMOURGOS','650.123.5234','1999-11-16','ST_MAN',5800.00,NULL,100,50),(125,'Julia','Nayer','JNAYER','650.124.1214','1997-07-16','ST_CLERK',3200.00,NULL,120,50),(126,'Irene','Mikkilineni','IMIKKILI','650.124.1224','1998-09-28','ST_CLERK',2700.00,NULL,120,50),(127,'James','Landry','JLANDRY','650.124.1334','1999-01-14','ST_CLERK',2400.00,NULL,120,50),(128,'Steven','Markle','SMARKLE','650.124.1434','2000-03-08','ST_CLERK',2200.00,NULL,120,50),(129,'Laura','Bissot','LBISSOT','650.124.5234','1997-08-20','ST_CLERK',3300.00,NULL,121,50),(130,'Mozhe','Atkinson','MATKINSO','650.124.6234','1997-10-30','ST_CLERK',2800.00,NULL,121,50),(131,'James','Marlow','JAMRLOW','650.124.7234','1997-02-16','ST_CLERK',2500.00,NULL,121,50),(132,'TJ','Olson','TJOLSON','650.124.8234','1999-04-10','ST_CLERK',2100.00,NULL,121,50),(133,'Jason','Mallin','JMALLIN','650.127.1934','1996-06-14','ST_CLERK',3300.00,NULL,122,50),(134,'Michael','Rogers','MROGERS','650.127.1834','1998-08-26','ST_CLERK',2900.00,NULL,122,50),(135,'Ki','Gee','KGEE','650.127.1734','1999-12-12','ST_CLERK',2400.00,NULL,122,50),(136,'Hazel','Philtanker','HPHILTAN','650.127.1634','2000-02-06','ST_CLERK',2200.00,NULL,122,50),(137,'Renske','Ladwig','RLADWIG','650.121.1234','1995-07-14','ST_CLERK',3600.00,NULL,123,50),(138,'Stephen','Stiles','SSTILES','650.121.2034','1997-10-26','ST_CLERK',3200.00,NULL,123,50),(139,'John','Seo','JSEO','650.121.2019','1998-02-12','ST_CLERK',2700.00,NULL,123,50),(140,'Joshua','Patel','JPATEL','650.121.1834','1998-04-06','ST_CLERK',2500.00,NULL,123,50),(141,'Trenna','Rajs','TRAJS','650.121.8009','1995-10-17','ST_CLERK',3500.00,NULL,124,50),(142,'Curtis','Davies','CDAVIES','650.121.2994','1997-01-29','ST_CLERK',3100.00,NULL,124,50),(143,'Randall','Matos','RMATOS','650.121.2874','1998-03-15','ST_CLERK',2600.00,NULL,124,50),(144,'Peter','Vargas','PVARGAS','650.121.2004','1998-07-09','ST_CLERK',2500.00,NULL,124,50),(145,'John','Russell','JRUSSEL','011.44.1344.429268','1996-10-01','SA_MAN',14000.00,0.40,100,80),(146,'Karen','Partners','KPARTNER','011.44.1344.467268','1997-01-05','SA_MAN',13500.00,0.30,100,80),(147,'Alberto','Errazuriz','AERRAZUR','011.44.1344.429278','1997-03-10','SA_MAN',12000.00,0.30,100,80),(148,'Gerald','Cambrault','GCAMBRAU','011.44.1344.619268','1999-10-15','SA_MAN',11000.00,0.30,100,80),(149,'Eleni','Zlotkey','EZLOTKEY','011.44.1344.429018','2000-01-29','SA_MAN',10500.00,0.20,100,80),(150,'Peter','Tucker','PTUCKER','011.44.1344.129268','1997-01-30','SA_REP',10000.00,0.30,145,80),(151,'David','Bernstein','DBERNSTE','011.44.1344.345268','1997-03-24','SA_REP',9500.00,0.25,145,80),(152,'Peter','Hall','PHALL','011.44.1344.478968','1997-08-20','SA_REP',9000.00,0.25,145,80),(153,'Christopher','Olsen','COLSEN','011.44.1344.498718','1998-03-30','SA_REP',8000.00,0.20,145,80),(154,'Nanette','Cambrault','NCAMBRAU','011.44.1344.987668','1998-12-09','SA_REP',7500.00,0.20,145,80),(155,'Oliver','Tuvault','OTUVAULT','011.44.1344.486508','1999-11-23','SA_REP',7000.00,0.15,145,80),(156,'Janette','King','JKING','011.44.1345.429268','1996-01-30','SA_REP',10000.00,0.35,146,80),(157,'Patrick','Sully','PSULLY','011.44.1345.929268','1996-03-04','SA_REP',9500.00,0.35,146,80),(158,'Allan','McEwen','AMCEWEN','011.44.1345.829268','1996-08-01','SA_REP',9000.00,0.35,146,80),(159,'Lindsey','Smith','LSMITH','011.44.1345.729268','1997-03-10','SA_REP',8000.00,0.30,146,80),(160,'Louise','Doran','LDORAN','011.44.1345.629268','1997-12-15','SA_REP',7500.00,0.30,146,80),(161,'Sarath','Sewall','SSEWALL','011.44.1345.529268','1998-11-03','SA_REP',7000.00,0.25,146,80),(162,'Clara','Vishney','CVISHNEY','011.44.1346.129268','1997-11-11','SA_REP',10500.00,0.25,147,80),(163,'Danielle','Greene','DGREENE','011.44.1346.229268','1999-03-19','SA_REP',9500.00,0.15,147,80),(164,'Mattea','Marvins','MMARVINS','011.44.1346.329268','2000-01-24','SA_REP',7200.00,0.10,147,80),(165,'David','Lee','DLEE','011.44.1346.529268','2000-02-23','SA_REP',6800.00,0.10,147,80),(166,'Sundar','Ande','SANDE','011.44.1346.629268','2000-03-24','SA_REP',6400.00,0.10,147,80),(167,'Amit','Banda','ABANDA','011.44.1346.729268','2000-04-21','SA_REP',6200.00,0.10,147,80),(168,'Lisa','Ozer','LOZER','011.44.1343.929268','1997-03-11','SA_REP',11500.00,0.25,148,80),(169,'Harrison','Bloom','HBLOOM','011.44.1343.829268','1998-03-23','SA_REP',10000.00,0.20,148,80),(170,'Tayler','Fox','TFOX','011.44.1343.729268','1998-01-24','SA_REP',9600.00,0.20,148,80),(171,'William','Smith','WSMITH','011.44.1343.629268','1999-02-23','SA_REP',7400.00,0.15,148,80),(172,'Elizabeth','Bates','EBATES','011.44.1343.529268','1999-03-24','SA_REP',7300.00,0.15,148,80),(173,'Sundita','Kumar','SKUMAR','011.44.1343.329268','2000-04-21','SA_REP',6100.00,0.10,148,80),(174,'Ellen','Abel','EABEL','011.44.1644.429267','1996-05-11','SA_REP',11000.00,0.30,149,80),(175,'Alyssa','Hutton','AHUTTON','011.44.1644.429266','1997-03-19','SA_REP',8800.00,0.25,149,80),(176,'Jonathon','Taylor','JTAYLOR','011.44.1644.429265','1998-03-24','SA_REP',8600.00,0.20,149,80),(177,'Jack','Livingston','JLIVINGS','011.44.1644.429264','1998-04-23','SA_REP',8400.00,0.20,149,80),(178,'Kimberely','Grant','KGRANT','011.44.1644.429263','1999-05-24','SA_REP',7000.00,0.15,149,NULL),(179,'Charles','Johnson','CJOHNSON','011.44.1644.429262','2000-01-04','SA_REP',6200.00,0.10,149,80),(180,'Winston','Taylor','WTAYLOR','650.507.9876','1998-01-24','SH_CLERK',3200.00,NULL,120,50),(181,'Jean','Fleaur','JFLEAUR','650.507.9877','1998-02-23','SH_CLERK',3100.00,NULL,120,50),(182,'Martha','Sullivan','MSULLIVA','650.507.9878','1999-06-21','SH_CLERK',2500.00,NULL,120,50),(183,'Girard','Geoni','GGEONI','650.507.9879','2000-02-03','SH_CLERK',2800.00,NULL,120,50),(184,'Nandita','Sarchand','NSARCHAN','650.509.1876','1996-01-27','SH_CLERK',4200.00,NULL,121,50),(185,'Alexis','Bull','ABULL','650.509.2876','1997-02-20','SH_CLERK',4100.00,NULL,121,50),(186,'Julia','Dellinger','JDELLING','650.509.3876','1998-06-24','SH_CLERK',3400.00,NULL,121,50),(187,'Anthony','Cabrio','ACABRIO','650.509.4876','1999-02-07','SH_CLERK',3000.00,NULL,121,50),(188,'Kelly','Chung','KCHUNG','650.505.1876','1997-06-14','SH_CLERK',3800.00,NULL,122,50),(189,'Jennifer','Dilly','JDILLY','650.505.2876','1997-08-13','SH_CLERK',3600.00,NULL,122,50),(190,'Timothy','Gates','TGATES','650.505.3876','1998-07-11','SH_CLERK',2900.00,NULL,122,50),(191,'Randall','Perkins','RPERKINS','650.505.4876','1999-12-19','SH_CLERK',2500.00,NULL,122,50),(192,'Sarah','Bell','SBELL','650.501.1876','1996-02-04','SH_CLERK',4000.00,NULL,123,50),(193,'Britney','Everett','BEVERETT','650.501.2876','1997-03-03','SH_CLERK',3900.00,NULL,123,50),(194,'Samuel','McCain','SMCCAIN','650.501.3876','1998-07-01','SH_CLERK',3200.00,NULL,123,50),(195,'Vance','Jones','VJONES','650.501.4876','1999-03-17','SH_CLERK',2800.00,NULL,123,50),(196,'Alana','Walsh','AWALSH','650.507.9811','1998-04-24','SH_CLERK',3100.00,NULL,124,50),(197,'Kevin','Feeney','KFEENEY','650.507.9822','1998-05-23','SH_CLERK',3000.00,NULL,124,50),(198,'Donald','OConnell','DOCONNEL','650.507.9833','1999-06-21','SH_CLERK',2600.00,NULL,124,50),(199,'Douglas','Grant','DGRANT','650.507.9844','2000-01-13','SH_CLERK',2600.00,NULL,124,50),(200,'Jennifer','Whalen','JWHALEN','515.123.4444','1987-09-17','AD_ASST',4400.00,NULL,101,10),(201,'Michael','Hartstein','MHARTSTE','515.123.5555','1996-02-17','MK_MAN',13000.00,NULL,100,20),(202,'Pat','Fay','PFAY','603.123.6666','1997-08-17','MK_REP',6000.00,NULL,201,20),(203,'Susan','Mavris','SMAVRIS','515.123.7777','1994-06-07','HR_REP',6500.00,NULL,101,40),(204,'Hermann','Baer','HBAER','515.123.8888','1994-06-07','PR_REP',10000.00,NULL,101,70),(205,'Shelley','Higgins','SHIGGINS','515.123.8080','1994-06-07','AC_MGR',12000.00,NULL,101,110),(206,'William','Gietz','WGIETZ','515.123.8181','1994-06-07','AC_ACCOUNT',8300.00,NULL,205,110);
/*Table structure for table `job_grades` */
DROP TABLE IF EXISTS `job_grades`;
CREATE TABLE `job_grades` (
`grade_level` varchar(3) DEFAULT NULL,
`lowest_sal` int(11) DEFAULT NULL,
`highest_sal` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `job_grades` */
insert into `job_grades`(`grade_level`,`lowest_sal`,`highest_sal`) values ('A',1000,2999),('B',3000,5999),('C',6000,9999),('D',10000,14999),('E',15000,24999),('F',25000,40000);
/*Table structure for table `job_history` */
DROP TABLE IF EXISTS `job_history`;
CREATE TABLE `job_history` (
`employee_id` int(6) NOT NULL,
`start_date` date NOT NULL,
`end_date` date NOT NULL,
`job_id` varchar(10) NOT NULL,
`department_id` int(4) DEFAULT NULL,
PRIMARY KEY (`employee_id`,`start_date`),
UNIQUE KEY `jhist_emp_id_st_date_pk` (`employee_id`,`start_date`),
KEY `jhist_job_fk` (`job_id`),
KEY `jhist_dept_fk` (`department_id`),
CONSTRAINT `jhist_dept_fk` FOREIGN KEY (`department_id`) REFERENCES `departments` (`department_id`),
CONSTRAINT `jhist_emp_fk` FOREIGN KEY (`employee_id`) REFERENCES `employees` (`employee_id`),
CONSTRAINT `jhist_job_fk` FOREIGN KEY (`job_id`) REFERENCES `jobs` (`job_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `job_history` */
insert into `job_history`(`employee_id`,`start_date`,`end_date`,`job_id`,`department_id`) values (101,'1989-09-21','1993-10-27','AC_ACCOUNT',110),(101,'1993-10-28','1997-03-15','AC_MGR',110),(102,'1993-01-13','1998-07-24','IT_PROG',60),(114,'1998-03-24','1999-12-31','ST_CLERK',50),(122,'1999-01-01','1999-12-31','ST_CLERK',50),(176,'1998-03-24','1998-12-31','SA_REP',80),(176,'1999-01-01','1999-12-31','SA_MAN',80),(200,'1987-09-17','1993-06-17','AD_ASST',90),(200,'1994-07-01','1998-12-31','AC_ACCOUNT',90),(201,'1996-02-17','1999-12-19','MK_REP',20);
/*Table structure for table `jobs` */
DROP TABLE IF EXISTS `jobs`;
CREATE TABLE `jobs` (
`job_id` varchar(10) NOT NULL DEFAULT '',
`job_title` varchar(35) NOT NULL,
`min_salary` int(6) DEFAULT NULL,
`max_salary` int(6) DEFAULT NULL,
PRIMARY KEY (`job_id`),
UNIQUE KEY `job_id_pk` (`job_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `jobs` */
insert into `jobs`(`job_id`,`job_title`,`min_salary`,`max_salary`) values ('AC_ACCOUNT','Public Accountant',4200,9000),('AC_MGR','Accounting Manager',8200,16000),('AD_ASST','Administration Assistant',3000,6000),('AD_PRES','President',20000,40000),('AD_VP','Administration Vice President',15000,30000),('FI_ACCOUNT','Accountant',4200,9000),('FI_MGR','Finance Manager',8200,16000),('HR_REP','Human Resources Representative',4000,9000),('IT_PROG','Programmer',4000,10000),('MK_MAN','Marketing Manager',9000,15000),('MK_REP','Marketing Representative',4000,9000),('PR_REP','Public Relations Representative',4500,10500),('PU_CLERK','Purchasing Clerk',2500,5500),('PU_MAN','Purchasing Manager',8000,15000),('SA_MAN','Sales Manager',10000,20000),('SA_REP','Sales Representative',6000,12000),('SH_CLERK','Shipping Clerk',2500,5500),('ST_CLERK','Stock Clerk',2000,5000),('ST_MAN','Stock Manager',5500,8500);
/*Table structure for table `locations` */
DROP TABLE IF EXISTS `locations`;
CREATE TABLE `locations` (
`location_id` int(4) NOT NULL DEFAULT '0',
`street_address` varchar(40) DEFAULT NULL,
`postal_code` varchar(12) DEFAULT NULL,
`city` varchar(30) NOT NULL,
`state_province` varchar(25) DEFAULT NULL,
`country_id` char(2) DEFAULT NULL,
PRIMARY KEY (`location_id`),
UNIQUE KEY `loc_id_pk` (`location_id`),
KEY `loc_c_id_fk` (`country_id`),
CONSTRAINT `loc_c_id_fk` FOREIGN KEY (`country_id`) REFERENCES `countries` (`country_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `locations` */
insert into `locations`(`location_id`,`street_address`,`postal_code`,`city`,`state_province`,`country_id`) values (1000,'1297 Via Cola di Rie','00989','Roma',NULL,'IT'),(1100,'93091 Calle della Testa','10934','Venice',NULL,'IT'),(1200,'2017 Shinjuku-ku','1689','Tokyo','Tokyo Prefecture','JP'),(1300,'9450 Kamiya-cho','6823','Hiroshima',NULL,'JP'),(1400,'2014 Jabberwocky Rd','26192','Southlake','Texas','US'),(1500,'2011 Interiors Blvd','99236','South San Francisco','California','US'),(1600,'2007 Zagora St','50090','South Brunswick','New Jersey','US'),(1700,'2004 Charade Rd','98199','Seattle','Washington','US'),(1800,'147 Spadina Ave','M5V 2L7','Toronto','Ontario','CA'),(1900,'6092 Boxwood St','YSW 9T2','Whitehorse','Yukon','CA'),(2000,'40-5-12 Laogianggen','190518','Beijing',NULL,'CN'),(2100,'1298 Vileparle (E)','490231','Bombay','Maharashtra','IN'),(2200,'12-98 Victoria Street','2901','Sydney','New South Wales','AU'),(2300,'198 Clementi North','540198','Singapore',NULL,'SG'),(2400,'8204 Arthur St',NULL,'London',NULL,'UK'),(2500,'Magdalen Centre, The Oxford Science Park','OX9 9ZB','Oxford','Oxford','UK'),(2600,'9702 Chester Road','09629850293','Stretford','Manchester','UK'),(2700,'Schwanthalerstr. 7031','80925','Munich','Bavaria','DE'),(2800,'Rua Frei Caneca 1360 ','01307-002','Sao Paulo','Sao Paulo','BR'),(2900,'20 Rue des Corps-Saints','1730','Geneva','Geneve','CH'),(3000,'Murtenstrasse 921','3095','Bern','BE','CH'),(3100,'Pieter Breughelstraat 837','3029SK','Utrecht','Utrecht','NL'),(3200,'Mariano Escobedo 9991','11932','Mexico City','Distrito Federal,','MX');
/*Table structure for table `order` */
DROP TABLE IF EXISTS `order`;
CREATE TABLE `order` (
`order_id` int(11) DEFAULT NULL,
`order_name` varchar(15) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `order` */
insert into `order`(`order_id`,`order_name`) values (1,'shkstart'),(2,'tomcat'),(3,'dubbo');
/*Table structure for table `regions` */
DROP TABLE IF EXISTS `regions`;
CREATE TABLE `regions` (
`region_id` int(11) NOT NULL,
`region_name` varchar(25) DEFAULT NULL,
PRIMARY KEY (`region_id`),
UNIQUE KEY `reg_id_pk` (`region_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
/*Data for the table `regions` */
insert into `regions`(`region_id`,`region_name`) values (1,'Europe'),(2,'Americas'),(3,'Asia'),(4,'Middle East and Africa');
/*Table structure for table `emp_details_view` */
DROP TABLE IF EXISTS `emp_details_view`;
/*!50001 DROP VIEW IF EXISTS `emp_details_view` */;
/*!50001 DROP TABLE IF EXISTS `emp_details_view` */;
/*!50001 CREATE TABLE `emp_details_view`(
`employee_id` int(6) ,
`job_id` varchar(10) ,
`manager_id` int(6) ,
`department_id` int(4) ,
`location_id` int(4) ,
`country_id` char(2) ,
`first_name` varchar(20) ,
`last_name` varchar(25) ,
`salary` double(8,2) ,
`commission_pct` double(2,2) ,
`department_name` varchar(30) ,
`job_title` varchar(35) ,
`city` varchar(30) ,
`state_province` varchar(25) ,
`country_name` varchar(40) ,
`region_name` varchar(25)
)*/;
/*View structure for view emp_details_view */
/*!50001 DROP TABLE IF EXISTS `emp_details_view` */;
/*!50001 DROP VIEW IF EXISTS `emp_details_view` */;
/*!50001 CREATE ALGORITHM=UNDEFINED DEFINER=`root`@`localhost` SQL SECURITY DEFINER VIEW `emp_details_view` AS select `e`.`employee_id` AS `employee_id`,`e`.`job_id` AS `job_id`,`e`.`manager_id` AS `manager_id`,`e`.`department_id` AS `department_id`,`d`.`location_id` AS `location_id`,`l`.`country_id` AS `country_id`,`e`.`first_name` AS `first_name`,`e`.`last_name` AS `last_name`,`e`.`salary` AS `salary`,`e`.`commission_pct` AS `commission_pct`,`d`.`department_name` AS `department_name`,`j`.`job_title` AS `job_title`,`l`.`city` AS `city`,`l`.`state_province` AS `state_province`,`c`.`country_name` AS `country_name`,`r`.`region_name` AS `region_name` from (((((`employees` `e` join `departments` `d`) join `jobs` `j`) join `locations` `l`) join `countries` `c`) join `regions` `r`) where ((`e`.`department_id` = `d`.`department_id`) and (`d`.`location_id` = `l`.`location_id`) and (`l`.`country_id` = `c`.`country_id`) and (`c`.`region_id` = `r`.`region_id`) and (`j`.`job_id` = `e`.`job_id`)) */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
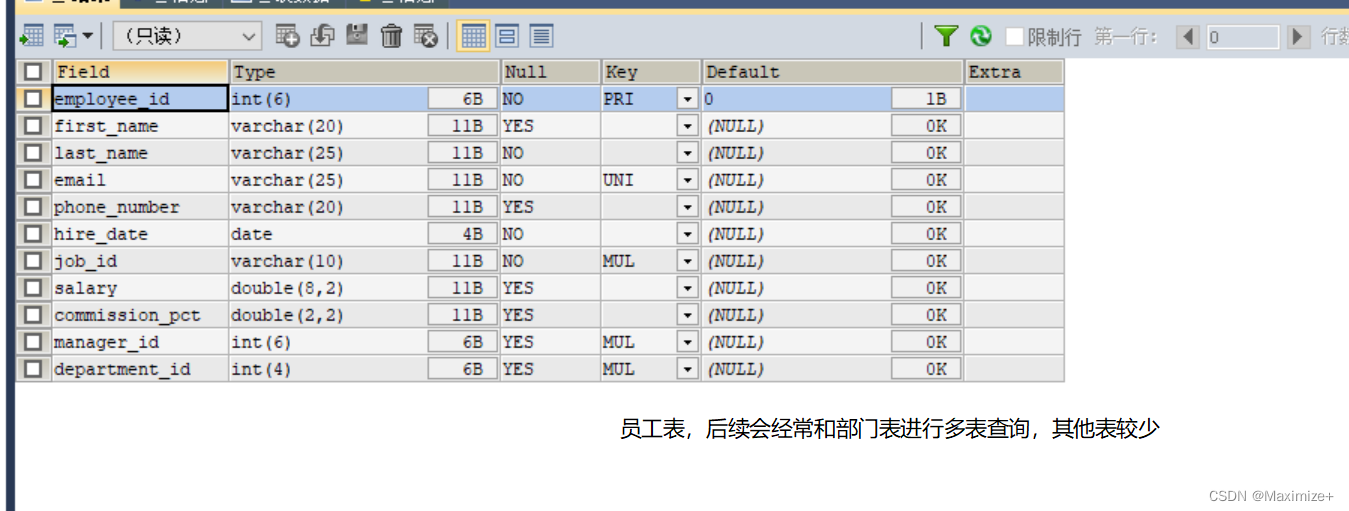
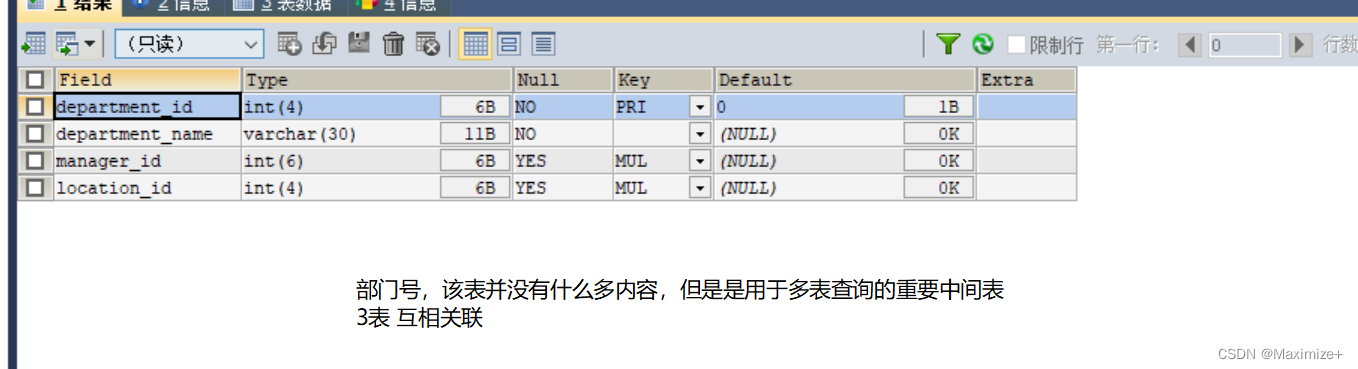
实际有9张,此处仅仅列出了2张常用表
员工表
部门表
其他表
如果用到的时候,会专门放出来的
入门基本语句
最基本的SELECT…FROM结构
我们首先学习以下最基本的SELECT语句,学习结构和一些基本常数查询和虚表了解
#最基本的SELECT语句:SELECT 字段1、字段2...FROM 表名
SELECT 1;#没有任何子句
SELECT 9/2;#没有任何子句
SELECT 1+1
FROM DUAL;#伪表
# *:表中的所有字段(或列)
SELECT*FROM employees;
#查询具体列
SELECT employee_id,last_name,salary
FROM employees;
列的别名_去重_NULL_DESC等操作
在开发中,Java的对象和数据库的对象的命名规则是不一样的,所以需要起别名来改变映射,来适应Java的底层反射,不过在平常的MySQL查询中,别名也是非常常用和实用的操作
列的别名
#列的别名
#查询返回的结果集合称为结果集:resultSet
#它们都可以完成别名效果,但是如果你起的别名是有空格的,则一定要添加''来使用,否则会报错,添加AS则可读性会好一些
SELECT employee_id AS "emp_id",last_name AS "emp_name",department_id AS "emp_dept_id"
FROM employees;
SELECT employee_id "emp_id",last_name "emp_name",department_id "emp_dept_id"
FROM employees;
SELECT employee_id emp_id,last_name emp_name,department_id emp_dept_id
FROM employees;
SELECT employee_id AS emp_id,last_name AS emp_name,department_id AS emp_dept_id
FROM employees;
#单引号别名也是可以的,但是只是MySQL的不严谨性
#MySQL的varchar字符串应该是单引号,但是双引号也可以,这是MySQL的不严谨,一定要养成使用 别名:双引号 字符串:单引号
INSERT INTO emp
VALUES(1002,"TOM");
在我们只需要知道有哪些分类时,就无需将每个分类都展现出来
去重
#去除重复行
#查询员工表中有哪些部门id
#使用关键字 -> distinct 去重
SELECT DISTINCT department_id
FROM employees;
在很多编程语言都是有NULL,而NULL通常不可以参与运算,大部分编程语言都是NULL运算等于NULL,Java遇到NULL对象属性也会直接抛出NULL空指针异常…
NULL
#空值参与运算
#1.空值:null
#2.null不等同于0,'','null'
SELECT NULL=0,NULL='',NULL=NULL;#正常情况应该是0或1,但是和NULL运算的结果全部是NULL
#查询奖金率,但是很多员工的奖金率是NULL(没有奖金率)
SELECT * FROM employees;
#查询月工资和年工资
#控制参与运算:结果一定为空
SELECT employee_id,salary "月工资",salary*(1+commission_pct)*12 "年工资",commission_pct
FROM employees;#错误的演示,因为有了控制运算会让查询结果直接是NULL
#使用了处理NULL的函数来解决问题
#如果字段不是NULL,则是多少就算多少,如果是NULL就用参数2来替换数值
SELECT employee_id,salary "月工资",salary*(1+IFNULL(commission_pct,0))*12 "年工资",commission_pct
FROM employees;#错误的演示,因为有了控制运算会让查询结果直接是NULL
在极少数情况下,我们声明的标识符会和官方定义的关键字重命,这时候再使用就需要添加着重号来告诉MySQL情况了
着重号
#着重号
#着重号一般是用来多表连接时添加的,系统喜欢自动添加着重号,不过最大意义是用来将关键字重名的字段区分为普通字段
#着重号是左上排数字键1的右边的~位置,不按Shift并且是英文状态按该键就是 ` 着重号
CREATE TABLE t(
NAME VARCHAR)
CREATE TABLE t(
`NAME` VARCHAR)
SELECT * FROM ORDER;
SELECT * FROM `ORDER`;
查询常数是使用较少的一种手段
查询常数
#查询常数
#该内容,查询记录有多少条记录,就生成多少条记录
SELECT '宝马三系','落地三十万+',employee_id,last_name
FROM employees;
查看表结构是非常常用的命令,通常用来验证属性的添加、修改等等操作
DESC操作
#显示表结构
#describe是desc的全称,而desc则是缩写,一般都常用desc,因为好拼和少
DESCRIBE employees;#显示了表中字段的详细信息
DESC employees;
DESC departments;
DESCRIBE departments;
使用WHERE过滤数据
在我们实际开发中,不可能总是查询表中所有的记录,这样会浪费大量的物资资源IO也会浪费时间和冗余的数据量,我们总是只需要有意义和有用的数据或内容,所以一个完整的查询一定是要有过滤数据的(除像select*from tableName这种情况)
#过滤数据
#基本结构
#SELECT...FROM...WHERE...
#查询90号部门员工的信息
SELECT *
FROM employees
WHERE department_id = 90;
#练习:查询last_name为'King'的员工信息
SELECT *
FROM employees#MySQL是大小写不敏感的
WHERE last_name = 'King';
基本SELECT查询课后练习
#基本的SELECT语句的课后练习
#1.查询员工12个月工资的总和,并起别名为ANNUAL SALARY
SELECT employee_id AS "员工号",first_name AS "名",last_name AS"姓",salary*(1+IFNULL(commission_pct,0))*12 AS "ANNUAL SALARY"
FROM employees;
#2.查询employees表中去除重复的job_id以后的数据
SELECT DISTINCT job_id
FROM employees
#3.查询工资大于12000的员工信息和工资
SELECT *
FROM employees
WHERE salary>12000;
#4.查询员工号为176的员工的姓名和部门号
SELECT * FROM employees
WHERE employee_id = 176;
#5.显示表departments的结构,并查询其中的全部数据
DESC departments;SELECT*FROM departments;
-----------------------------------------------
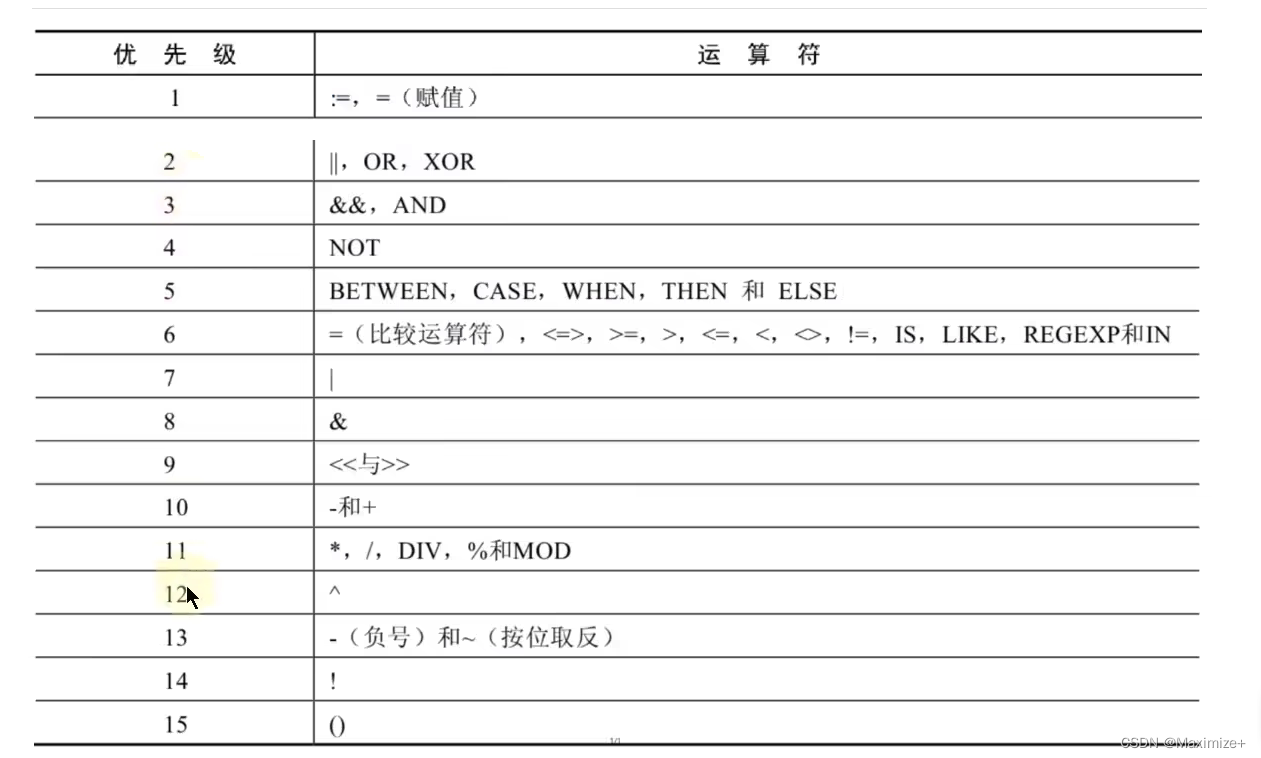
运算符
算术运算符的使用
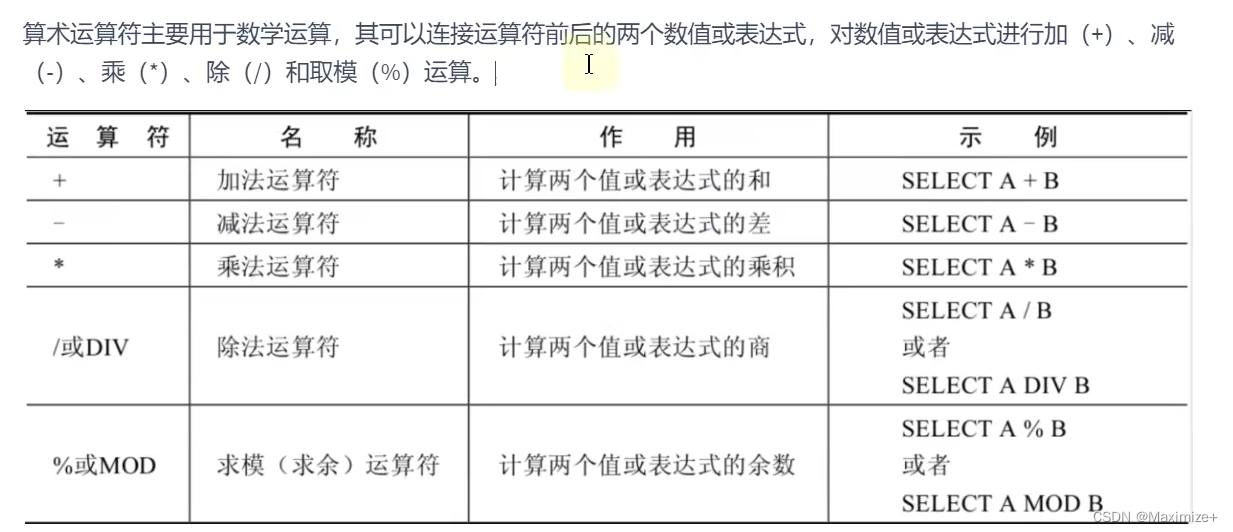
#运算符
#算术运算符: + - * / div % MOD
SELECT 100,100+0,100-0,100+50,100+50-30,100+35.5,100-35.5#整形和浮点型
FROM DUAL;#虚表
#MySQL的+号没有Java的拼接符的意思,这里是101结果,是底层隐式转换的结果
SELECT 100+'1'
FROM DUAL;
SELECT 100+'a'#此时将'a'看做0处理
FROM DUAL;
SELECT 100+NULL#NULL运算都为NULL
FROM DUAL;
SELECT 100,100*1,100*1.0,100/1.0,100/2,100+2*5/2,100/3,100 DIV 0 #分母如果为0则结果为NULL
FROM DUAL
#取模运算:% mod
SELECT 12%3,12%5,12 MOD -5 ,-12%5,-12%-5
FROM DUAL;
#练习:查询员工id为偶数的员工信息
SELECT employee_id,last_name,salary
FROM employees
WHERE employee_id % 2 = 0;
比较运算符的使用
比较运算符用来对表达式的操作数和右边的操作数进行比较,比较的结果为真则返回1,比较的结果为假则返回0,其他情况则返回NULL
比较运算符经常被用来作为SELECT查询语句的条件来使用,返回适合的条件的结果记录
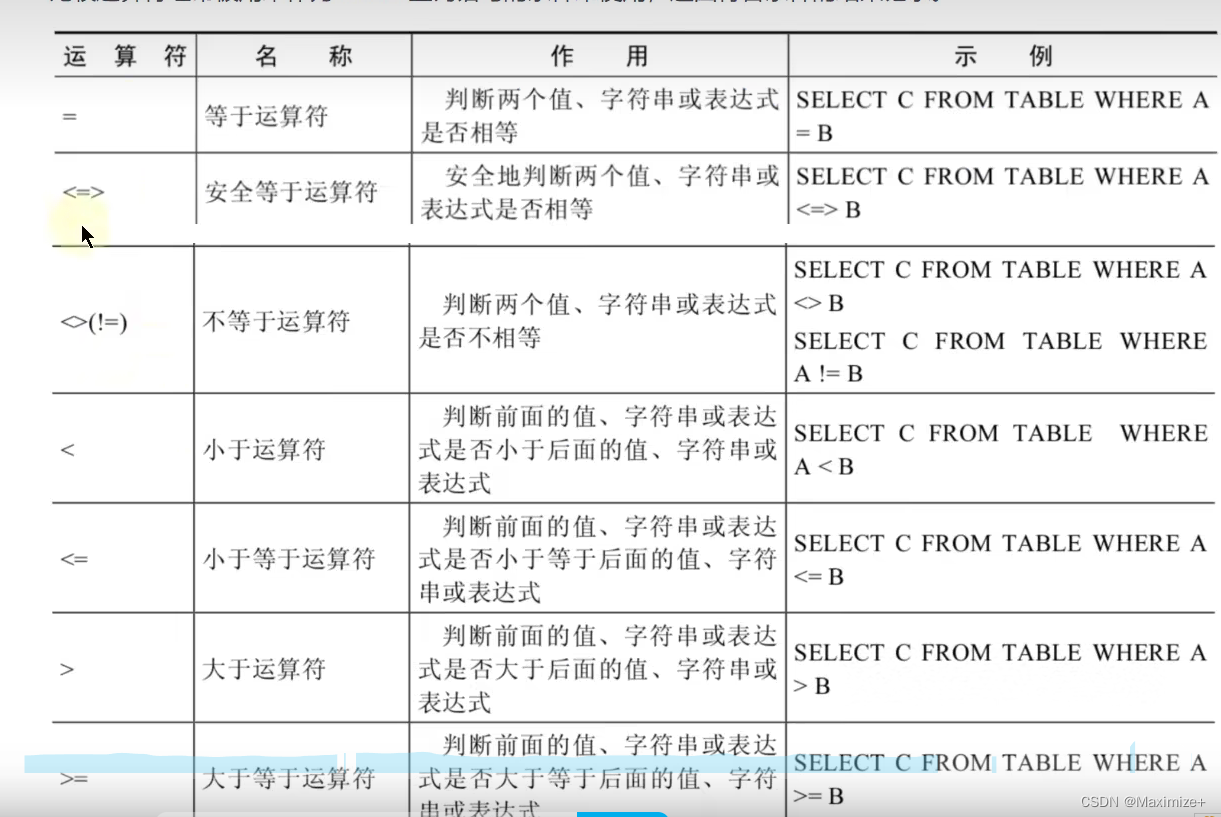

符号运算符
#比较运算符
# = <=> <> != < <= > >=
#如果为真 返回1
#如果为假 返回0
#如果为其他情况 返回NULL
SELECT 1 = 2,1!=2,1='1',1='a',0='a'#和四则运算那个道理一样 'a'不能隐式转换,所以是0
FROM DUAL;
#两边都是字符串的话,则按照ANSI的比较规则进行比较
SELECT 'a'='a','ab'='ab','a'='b'
FROM DUAL;
SELECT 1=NULL,NULL=NULL #只要有null参与判断,结果就为null
FROM DUAL;
SELECT last_name,salary
FROM employees
#where salary = 6000;
WHERE commission_pct = NULL;#不会有任何结果
#<=>:安全等于->为NULL而生
SELECT 1<=>2,1<=>'1',1<=>'a',0<=>'a'
FROM DUAL;
SELECT 1<=>NULL,NULL<=>NULL#结果0 1,当有NULL时结果是0,所以0=0
FROM DUAL;
SELECT last_name,salary,commission_pct
FROM employees
WHERE commission_pct <=> NULL;
SELECT 3<>2,'4'<>NULL,''!=NULL,NULL!=NULL
FROM DUAL;
非符号运算符
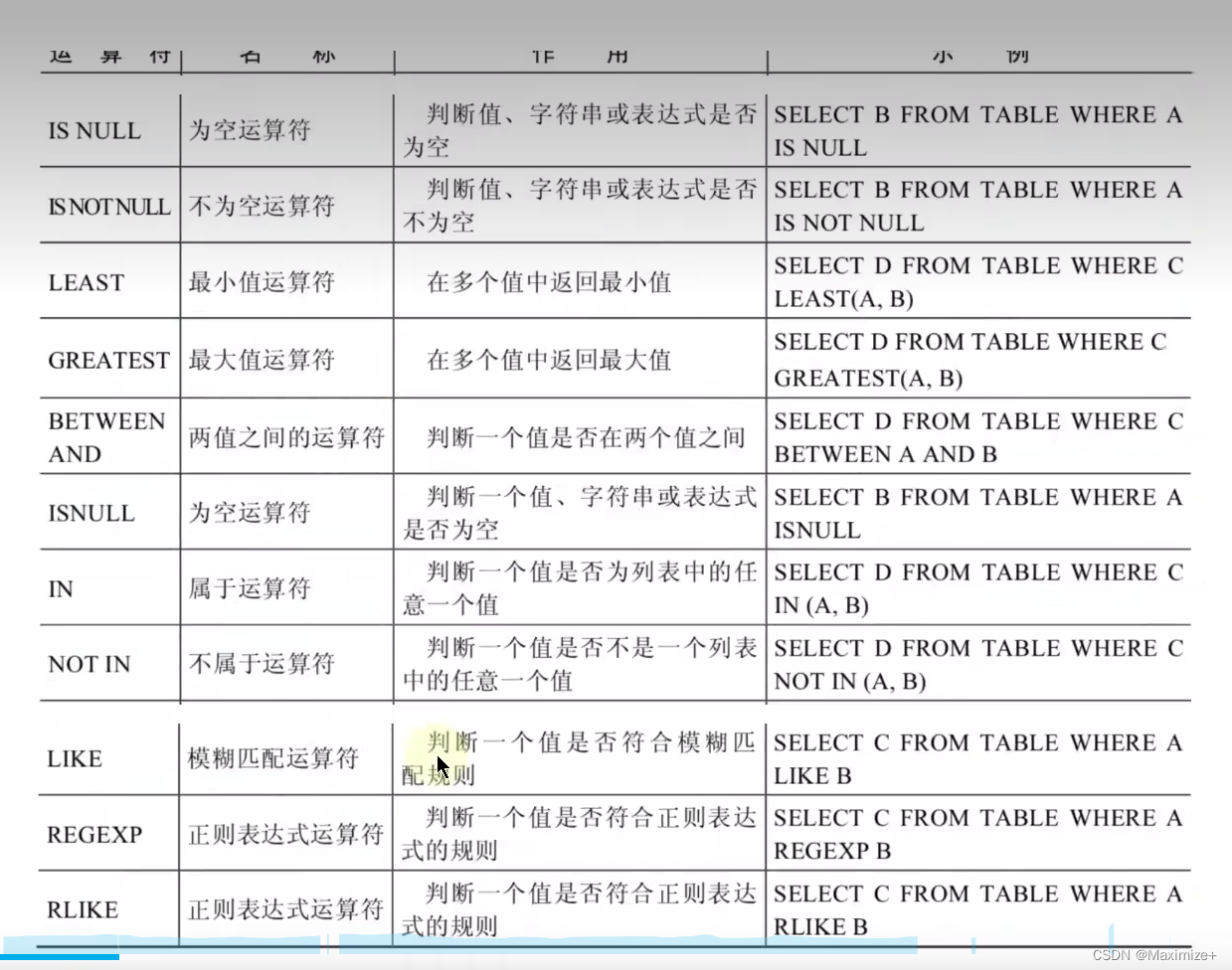
第一波
#非符号运算符
#IS NULL\IS NOT NULL\ISNULL
#练习:查询表中commission_pct为null的数据有哪些
SELECT last_name,salary,commission_pct
FROM employees
WHERE commission_pct IS NULL;和安全等于是一模一样的
#或
SELECT last_name,salary,commission_pct
FROM employees
WHERE ISNULL(commission_pct);
#练习:查询表中commission_pct不为null的数据有哪些
SELECT last_name,salary,commission_pct
FROM employees
WHERE commission_pct IS NOT NULL;#只查询不为NULL的数据
#或
SELECT last_name,salary,commission_pct
FROM employees
WHERE NOT commission_pct <=> NULL;
第二波
#LEAST()\GREATEST least greatest
SELECT LEAST('g','b','t','m'),GREATEST('g','b','t','m')#比较的是字母的顺序a-z
FROM DUAL;
#length -> 字符长度(个数)
SELECT LEAST(first_name,last_name),LEAST(LENGTH(first_name),LENGTH(last_name))
FROM employees;
#BETWEEN...AND
#查询工资在6000到8000的员工信息
#&&\AND:且 | or:或 | NOT:非
#where salary BETWEEN 6000 AND 8000;包括边界值
#WHERE salary >=6000 && salary<=8000;
WHERE salary >=6000 AND salary<=8000;#不要放过来写,会直接无结果的
#查询工资不在6000-8000的员工信息
SELECT employee_id,last_name,salary#between...and...
FROM employees
#WHERE salary <6000 or salary > 8000;
WHERE NOT salary BETWEEN 6000 AND 8000;#包括边界值
#in(set)\not in(set)
#连习:查询部门为10,20,30部门的员工信息
SELECT last_name,salary,department_id
FROM employees
WHERE department_id IN(10,20,30);#如果用 10 OR 20 OR 30是不靠谱的 因为20和30非0就看成1了,全都要了 所以要改为。department_id=20...
#练习:查询工资不是6000,7000,8000的员工信息
SELECT last_name,salary
FROM employees
WHERE NOT salary IN(6000,7000,8000);
#where salary NOT in(6000,7000,8000);
#LIKE:模糊查询
#练习:查询last_name中包含字符'a'的员工信息
SELECT last_name,first_name,salary
FROM employees
#如果是 'a%'那就表示名字以a开头的员工,如果是'%a'就表示名字以a结束的员工,其他的依次根据情况类推...
WHERE last_name LIKE '%a%';#忽略了大小写;'%a%' %表示前面有不确定个数的字符,%表示后面有不确定个数的字符
#练习last_name中包含字符'a'且包含字符'e'的员工信息
SELECT last_name,salary
FROM employees
#where last_name like '%a%' and last_name LIKE '%e%';
WHERE last_name LIKE '%a%e%' OR last_name LIKE '%e%a%';
#_:代表一个不确定的字符
#练习:查询第三个字符是'a'的员工信息
SELECT last_name
FROM employees
WHERE last_name LIKE '__a%';#中间不要加空格
#练习:查询第二个字符是_且第三个字符串是'a'的员工信息
#需要使用转义字符:\
SELECT last_name
FROM employees
WHERE last_name LIKE '_\_a%';
#或者(了解)
SELECT last_name
FROM employees
WHERE last_name LIKE '_$_a%' ESCAPE '$';#自定义转义字符 默认是斜线\表示转义
第三波
#REGEXP\RLIKE:正则表达式
#1:该字符串是否以s开头? 1
#2:该字符串是否以t结尾? 1
#3:该字符串是否包含hk? 1
SELECT 'shkstart' REGEXP '^s','shkstart' REGEXP 't$','shkstart' REGEXP 'hk'
FROM DUAL;
#1:是否包含gu?gu 中间有一个不确定的字符 1
#如果是 gu..gu 则是 0
#2:该字符串是否包含a或者包含b
SELECT 'atguigu' REGEXP 'gu.gu','atguigu' REGEXP '[ab]'
FROM DUAL;

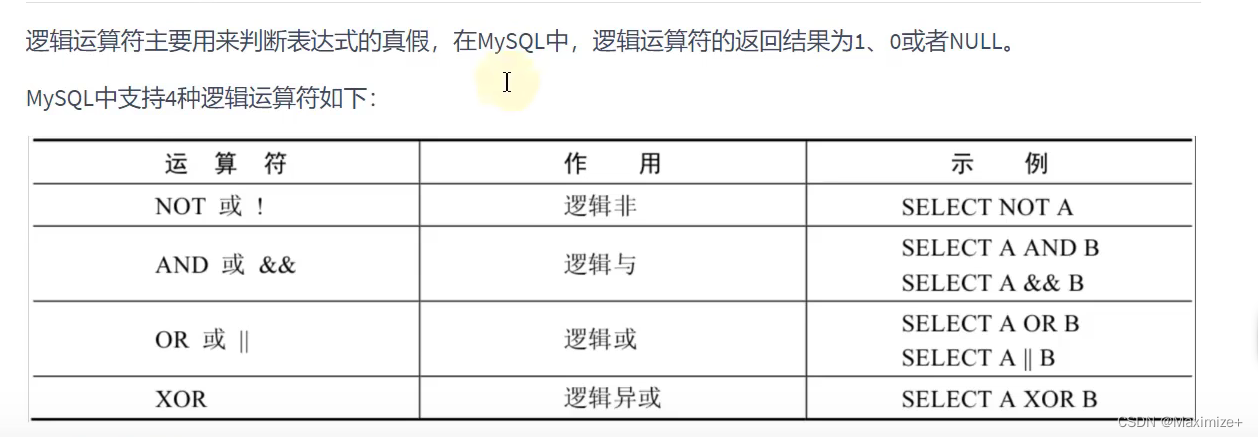
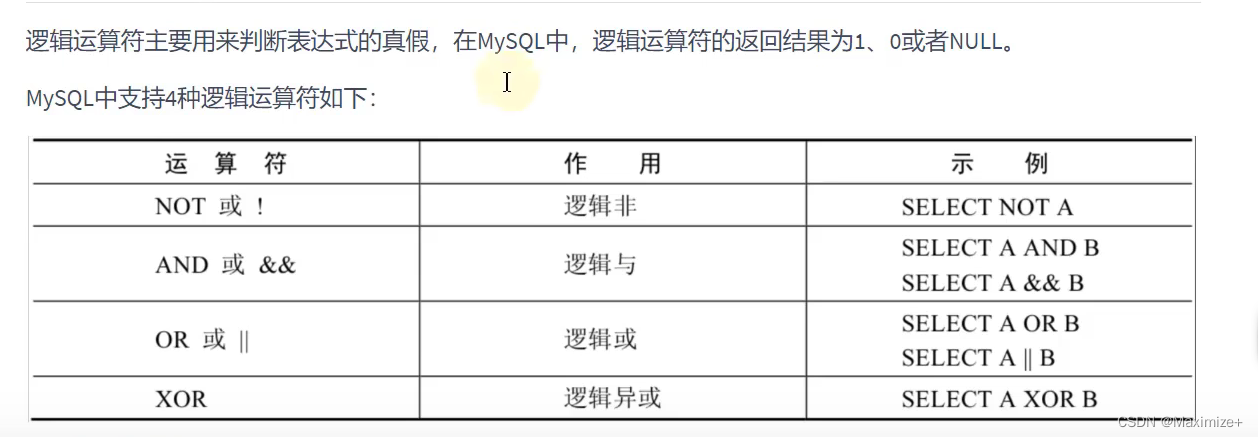
逻辑运算符与位运算符的使用
#逻辑运算符:OR || AND && NOT !XOR
#or and
SELECT employee_id,last_name,salary#between...and...
FROM employees
#WHERE department_id = 10 OR department_id = 20;#和IN一样
#在大部分情况下 尤其是唯一标识的字段属性,是绝对不应该满足2个相同记录类型条件的
#WHERE department_id = 10 AND department_id = 20;#既是10号部门又是20号部门,这样是不合理的是不会有结果的
WHERE department_id = 50 AND salary >6000;#此处是针对该表记录不同属性的查询 没有问题
#not
SELECT employee_id,last_name,salary#between...and...
FROM employees
#WHERE salary not between 6000 and 8000;查询工资不再6000和8000区间内的员工信息
#where commission_pct is NOT null;查询奖金率不为空的员工,如果去掉NOT 就是查询为NULL的
WHERE NOT commission_pct <=> NULL;#安全等于 不为NULL
#XOR
SELECT employee_id,last_name,salary
FROM employees
#如果工资大于6000 则一定没有50号部门
#如果是500部门则工资一定没有大于6000
WHERE department_id = 50 XOR salary > 6000;


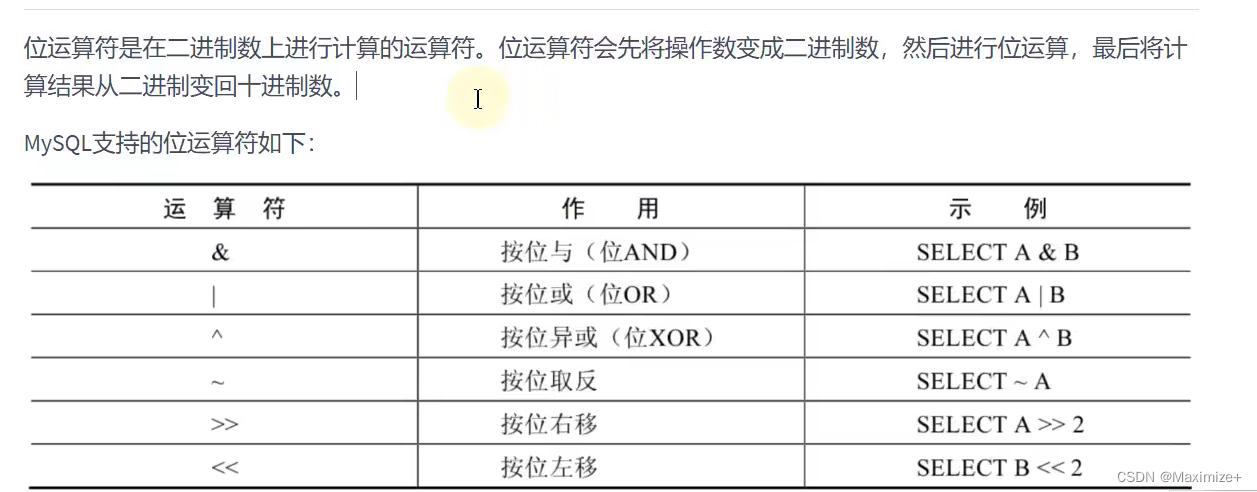
运算符练习
#1.选择工资不在5000到12000的员工的姓名和工资
SELECT employee_id,last_name,salary
FROM employees
#where salary not between 5000 AND 12000;
WHERE salary < 5000 OR salary > 12000;
#2.选择在20或50号部门的员工姓名和部门号
SELECT employee_id,last_name,salary,department_id
FROM employees
#WHERE department_id IN(20,50);
WHERE department_id = 20 OR department_id = 50;
#3.选择公司中没有管理者的员工姓名及job_id
SELECT employee_id,last_name,job_id
FROM employees
WHERE manager_id IS NULL;
#4.选择公司中有奖金的员工姓名、工资和奖金级别
SELECT last_name,salary,commission_pct
FROM employees
WHERE commission_pct IS NOT NULL;
#5.选择员工姓名的第三个字母是a的员工姓名
SELECT last_name
FROM employees
WHERE last_name LIKE '__a%';
#6.选择姓名中有字母a和k的员工姓名
SELECT last_name
FROM employees
#WHERE last_name LIKE '%a%' AND last_name LIKE '%k%';
WHERE last_name LIKE '%a%k%' OR last_name LIKE '%k%a%';
#7.显示出表employees表中first_name以'e'结尾的员工信息
SELECT first_name
FROM employees
WHERE first_name LIKE '%e';
#正则表达式
SELECT first_name
FROM employees
WHERE first_name REGEXP 'e$';#以e开头的写法:'^e'
#8.显示出表employees部门编号在 80-100之间的姓名、工种
SELECT last_name,job_id
FROM employees
#方式一:推荐
#where department_id between 80 AND 100;
#方式二:相同效果
#where department_id >=80 and department_id <=100;
#方式三:仅仅适用于这个区间只有这三个值的表
WHERE department_id IN (80,90,100);
#9.显示出表employees的manager_id 是100,101,110的员工的姓名、工资、管理者
SELECT employee_id,salary,manager_id
FROM employees
WHERE manager_id IN (100,101,110);
-----------------------------------------------
排序与分页
该内容是查询内容之一

ORDER BY实现排序操作
ORDER BY排序操作
#查询与排序
#排序
SELECT * FROM employees; #如果没有使用排序操作,则默认顺序是先后添加的顺序显示的
#练习:按照salary从高到底的顺序去显示员工信息
#使用ORDER BY 对查询得到的数据进行排序操作
#ORDER -> 排序 BY-> 使用...或用...
#升序:ASC(ascend)
#降序:DESC(descend)
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary DESC;#使用salary进行排序,DESC ->倒序 ASC->正序, 默认正序ASC
#我们可以使用列的别名,进行排序
#列的别名只能在order by 中使用,不能在WHERE中使用
#因为执行顺序:先看来自哪个表、然后看过滤条件,然后才是看要哪些数据
#先过滤再查条件,这样做可以提升效率等等,所以WHERE要早执行,是看不到别名的
SELECT employee_id,salary*12 annual_sal
FROM employees
#WHERE annual_sal > 10000
ORDER BY annual_sal;
#因为先过滤后查询所选字段,所以就出现了排序数据里只有 50 60 70的情况
#强调格式:WHERE必须写在FROM之后和ORDER BY 之前
SELECT employee_id,salary,department_id
FROM employees
WHERE department_id IN(50,60,70)
ORDER BY department_id DESC;
二级排序
在很多时候,有些事物都满足一个条件,比如价格…其中规格之一参数…
那么在这个时候就要出现第二个条件、第三个条件、…
所以也就有了二级排序、三级排序、…
内容并不多,不过也是后续实现业务层等等时的重要操作,尤其是像DAO层传输数据给Service层,然后Service再传输给Controller,控制器通过Tomcat服务器将数据传给浏览器,Thymeleaf再将数据渲染到页面上等等…
#二级排序
#练习:显示员工信息,按照department_id的降序排列,salary的升序排列
SELECT employee_id,salary,department_id
FROM employees
ORDER BY department_id DESC,salary ASC;#用逗号隔开,写后面的条件(等级排序)
LIMIT实现分页
在浏览器上,我们并不会将从数据库获取的数据全部都呈现在用户眼前,这样即冗余又会增加服务器后端的负压,而通过分页来进行部分分页或者异步操作(SpringMVC的ajx->vue内容)等等,所以我们需要通过分页来进行有限制的传输数据数量

#分页
#mysql使用limit实现数据的分页显示
#需求1:每页显示20条记录,此时显示第1页
SELECT employee_id,last_name
FROM employees
LIMIT 0,20;#0:偏移量,20:每页数据量
#需求2:每页显示20条记录,此时显示第2页
SELECT employee_id,last_name#
FROM employees
LIMIT 20,20;
#需求:每页显示pageSize条件记录,此时显示第pageNo页
#公式:LIMIT (pageNo-1) * pageSize,pageSize;
#LIMIT的格式:严格来说:LIMIT 位置偏移量,条目数
#结构"LIMIT 0,条目数" 等价于 "LIMIT 条目数"
#WHERE ... ORDER BY ...LIMIT声明顺序如下
SELECT employee_id,last_name,salary
FROM employees
WHERE salary>6000
ORDER BY salary DESC
LIMIT 10;
#练习:表里有107条数据,我们只想要显示第32、33条数据怎么办呢?
SELECT employee_id,last_name,salary
FROM employees
LIMIT 31,2;#31:从哪里开始... 2:条目数
#MySQL8.0新特性:LIMIT ... OFFSET ...
#练习:表里有107条数据,我们只想要显示第32、33条数据怎么办呢?
SELECT employee_id,last_name,salary
FROM employees
LIMIT 2 OFFSET 31;
#LIMIT 31 OFFSET 2;新特性将两者顺序颠倒了一下,使用上了关键字,可能可读性会更好一些
#练习:查询员工工资中最高的员工信息
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary DESC
#LIMIT 0,1;
LIMIT 1;
扩展

排序与分页练习
下一步就是多表查询了,大的要来了!!!
练习的内容也是比较简单的,可以一步一步的向下写,在后续的多表查询和子查询时,就要局部思考的去写了!
#排序与分页的练习
#1.查询员工的姓名和部门号和年薪,按年薪降序,按姓名升序显示
SELECT last_name,department_id,(salary*12) AS "annual_sal"
FROM employees
ORDER BY annual_sal DESC,last_name ASC;#默认升序,可以不写ASC,但是倒序必须写 DESC
#2.选择工资不在8000到17000的姓名和工资,按照工资降序,显示第21到40的位置
SELECT employee_id,last_name,salary
FROM employees
WHERE salary NOT BETWEEN 8000 AND 17000
ORDER BY salary DESC
LIMIT 20,20
#3.查询邮箱中包含e的员工信息,并先按邮箱的字节顺序降序,再按部门升序
SELECT employee_id,last_name,salary
FROM employees
#where email LIKE '%e%'
WHERE email REGEXP '[e]'
ORDER BY LENGTH(email) DESC,department_id ASC;
-----------------------------------------------
多表 查询
多表查询是MySQL的整个核心内容,非常考验自己对SQL语句的功底和对表结构等的理解和掌握程度,不过,不要害怕,只要自己认真学,真正写起来的时候其实也没有什么难度的
为什么需要多表查询


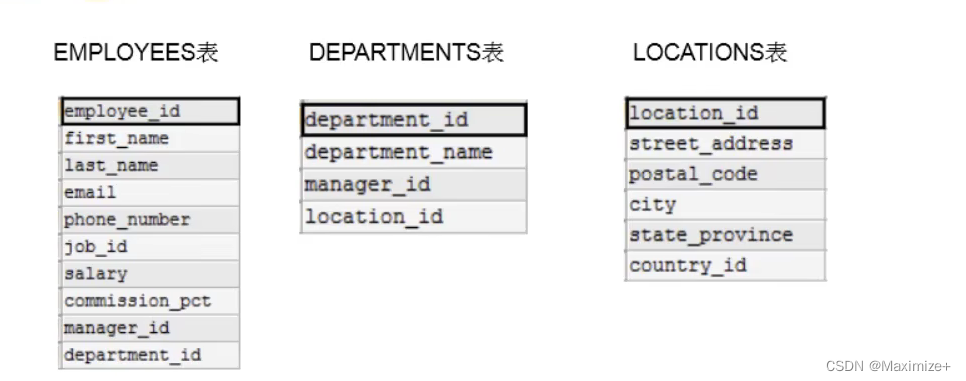
#多表查询
#查询员工名为'Abel'的人在哪个城市工作?
SELECT*
FROM employees
WHERE last_name = 'Abel';#部门id为80
SELECT*
FROM departments
WHERE department_id = 80;#可以看出部门为销售,城市id为2500(坐落地域)
SELECT *
FROM locations
WHERE location_id = 2500;
#通过上面三次查询,我们才知道该员工的部门号和工作城市
笛卡尔积的错误与正确的多表查询
笛卡尔积错误演示

#多表的查询如何实现?
#出现笛卡尔积错误
#笛卡尔积代表 x*y条记录,相当于手拉手问题,都结合运算了一次
#2889条记录 --> (employees)107*27(departments)
SELECT employee_id,department_name
FROM employees,departments;
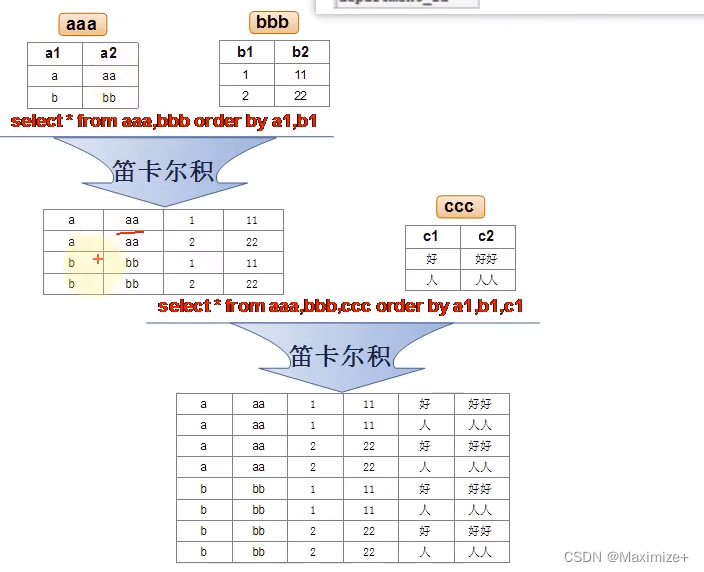
正确的多表连接
我们在进行多表连接查询时,应该有连接过滤条件的,并且是表1和表2有大致相等的字段所关联,才能有条有序的展现出来
#正确的多表连接条件
SELECT employee_id,department_name
FROM employees,departments
#两个表的连接条件
WHERE employees.department_id = departments.`department_id`;
#106条数据,在员工表中有一人没有部门,所以只展现了106条数据

扩展内容
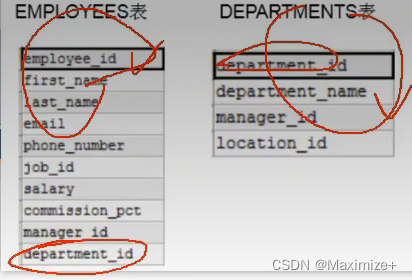
#下面语句是错误的,因为两个表都有department_id
#系统无法分析出到底是表1还是表2
SELECT employee_id,department_name,department_id
FROM employees,departments
#两个表的连接条件
WHERE employees.department_id = departments.`department_id`;
#----------------------------------------------------------------
#正确示范
#如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表
SELECT employee_id,department_name,employees.department_id
FROM employees,departments
#两个表的连接条件
WHERE employees.department_id = departments.`department_id`;
#建议:从sql优化角度来看,建议多表查询时,每个字段前都指明其所在的表
SELECT employees.employee_id,departments.department_name,employees.department_id
FROM employees,departments
#两个表的连接条件
WHERE employees.department_id = departments.`department_id`;
#问题:指明的表名太长,有些太冗余怎么办?
#我们可以为表起别名,但是如果一旦起了别名,在查询和WHERE中就只能用这个别名
#原因是执行顺序,先FROM 然后WHERE 然后SELECT...的原因
SELECT emp.employee_id ,dept.department_name,emp.department_id
FROM employees emp,departments dept#别名会覆盖掉原表名
#两个表的连接条件
WHERE emp.department_id = dept.`department_id`;
#如果有n个表实现多表查询,则需要n-1个连接条件
#练习:查询员工的employee_id,last_name,department_name,city
SELECT emp.employee_id,emp.last_name,dept.department_name,locat.city
FROM employees emp,departments dept,locations locat
WHERE emp.`department_id` = dept.`department_id`
AND dept.`location_id` = locat.`location_id`;#三个表都需要连接在一起,一一对应
等值连接VS非等值连接、自连接VS非自连接
等值连接VS非等值连接
#多表查询的分类
/*
角度1:等值连接 VS非等值连接
角度2:自连接 VS 非自连接
角度3:内连接 VS 外连接
*/
#等值连接 VS 非等值连接
#非等值连接的例子
SELECT*FROM job_grades;
#往常像员工表和部门表的emp.department_id = dept.department_id就是等值连接
SELECT e.last_name,e.salary,j.grade_level
FROM employees e,job_grades j
#where e.`salary` between j.`lowest_sal` and j.`highest_sal`;
WHERE e.salary>=j.`lowest_sal` AND e.salary <=j.`highest_sal`
ORDER BY j.grade_level ASC;
自然连接VS非自然连接
#自连接 VS 非自连接
#非自连接无非就是引用了外表的关联(连接字段)属性
#练习:查询每个员工的管理者
SELECT emp1.`employee_id`,emp1.`last_name`,emp2.`employee_id`,emp2.`last_name`
FROM employees emp1,employees emp2
WHERE emp1.`manager_id` = emp2.`employee_id`;
SQL92与99语法如何实现内连接和外连接
满足查询连接条件的结果集记录都被称为内连接,而不满足的就是外连接,有些时候,我们反而需要查询那些满不足条件的记录

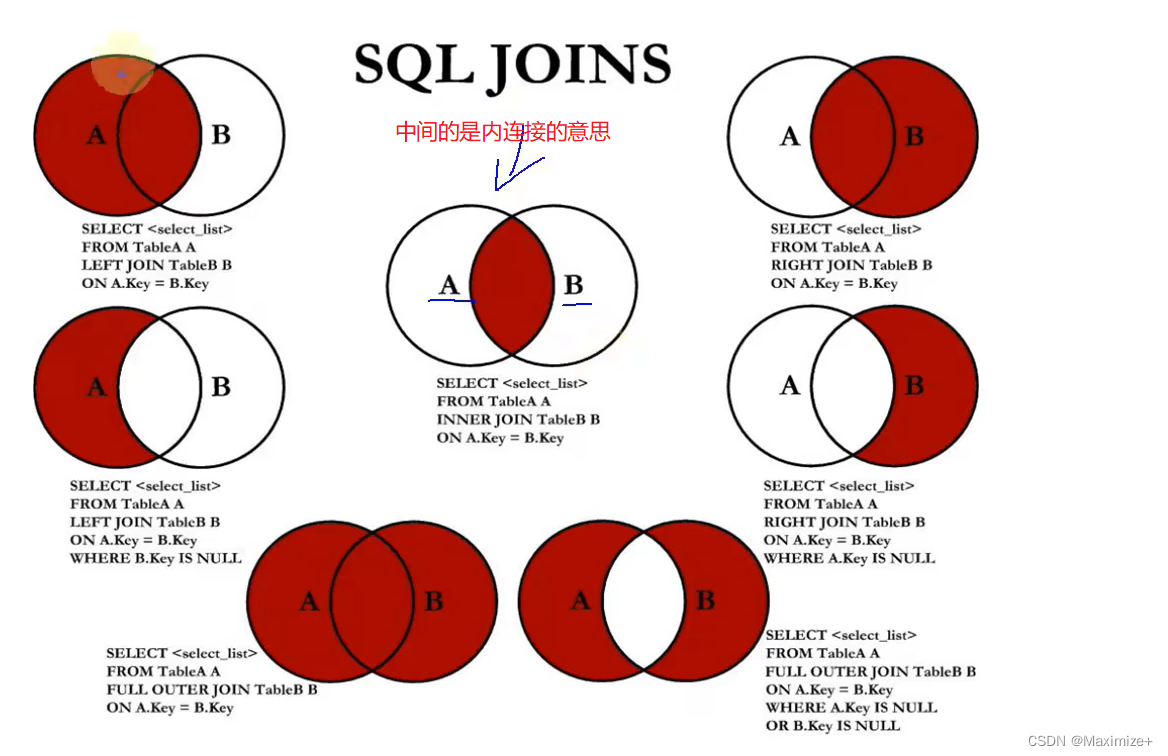
#内连接 VS 外连接
#内连接:合并具有同一列的两个以上的表的行,结果集中不包含一个表与另一个表不匹配的行
SELECT e.`employee_id`,d.`department_name`
FROM employees e,departments d
WHERE e.`department_id` = d.`department_id`;#106行
#如果想要将不符合查询条件的记录就叫外连接
#外连接:合并具有同一列的两个以上的表的行,结果集中除了包含一个表与另外一个另匹配的行之外
#还查询到了左表或右表中不匹配的行,也就是 107条
#外连接的分类:左外连接、右外连接、满外连接(都要)
#左外连接;两个表在连接过程中除了返回满足连接条件的行以外还返回左表中不满足条件的行
#右外连接;两个表在连接过程中除了返回满足连接条件的行以外还返回右表中不满足条件的行
#练习:查询所有员工的last_name,department_name信息(所有的,一定是外连接!)
SELECT e.`employee_id`,d.`department_name`
FROM employees e,departments d
WHERE e.`department_id` = d.`department_id`;#107行(包括了没有部门信息的员工信息——106+1条)
#SQL92语法实现内连接:见上,略
#SQL92语法实现外连接:使用+ --------------MySQL不支持SQL92语法中外连接的写法!
SELECT e.`employee_id`,d.`department_name`
FROM employees e,departments d
WHERE e.`department_id` = d.`department_id`(+);
#SQL99语法中使用JOIN...ON的方式实现多表查询。这种方式也能解决外连接的问题。MySQL是支持此种方式的
SELECT e.`employee_id`,d.`department_name`
FROM employees e JOIN departments d#普通内连接
ON e.`department_id` = d.`department_id`;#106条
#上次多表查询的实例
SELECT e.`employee_id`,d.`department_name`#INNER可以省略 表示内连接
FROM employees e INNER JOIN departments d#普通内连接
ON e.`department_id` = d.`department_id`
JOIN locations l
ON d.`location_id` = l.`location_id`;
SELECT e.`employee_id`,d.`department_name`
FROM employees e LEFT JOIN departments d#左外连接 指包含左表不符合条件的记录
ON e.`department_id` = d.`department_id`;#107条
SELECT e.`employee_id`,d.`department_name`
FROM employees e RIGHT JOIN departments d#右外连接 指包含左表符合条件的记录
ON e.`department_id` = d.`department_id`;#122条
#SQL99语句实现外连接
#练习:查询所有的员工last_name,department_name信息
SELECT last_name,department_name#OUTER表示外连接 OUTER可以省略
FROM employees t1 LEFT OUTER JOIN departments t2#左外连接
ON t1.`department_id` = t2.`department_id`;
#右外连接
SELECT last_name,department_name#OUTER表示外连接 OUTER可以省略
FROM employees t1 RIGHT OUTER JOIN departments t2#右外连接
ON t1.`department_id` = t2.`department_id`;
#满外连接
SELECT last_name,department_name#OUTER表示外连接 OUTER可以省略
FROM employees t1 FULL OUTER JOIN departments t2#全外连接,但是MySQL不支持这么写
ON t1.`department_id` = t2.`department_id`;
使用SQL99实现7种JOIN操作
内连接
左外连接
右外连接
全外连接
左+右外连接
只要左连接
只要右连接
这里左右说的是不满足条件的外连接,内连接是满足条件的连接,左外就是左+内,右外是右+内,全就是三者结合,也可以单个,比如内 、左、右,其实挺好理解的,知道上面图里,中间是内连接的内容就很好理解其他的连接含义!
UNION的使用

区别就是多了一个交集的部分
SetResult = (左+内)+(右+内)
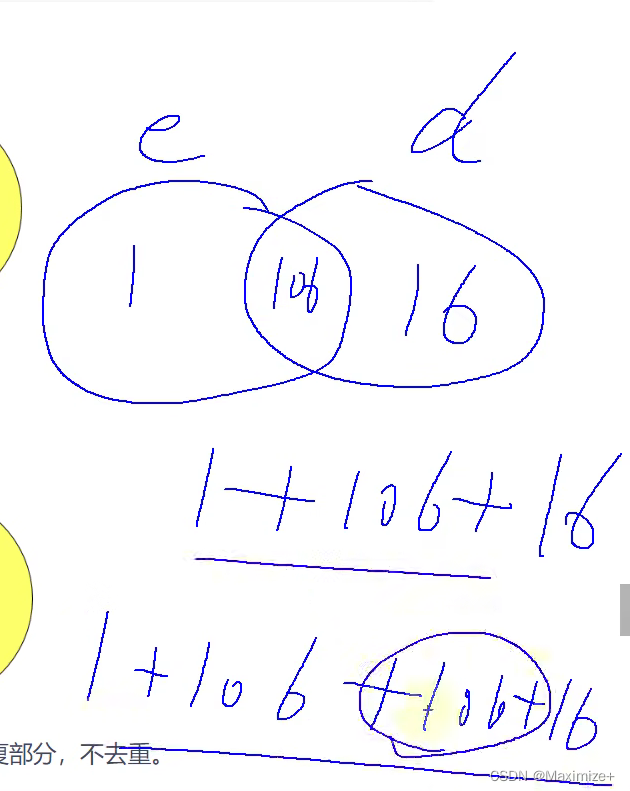

我们使用代码进行查询了一下,发现和上面图表的7个情况一样,没有什么难度
只要左外或右外不满足条件的记录的本质理解
我们可能会很疑惑,我们明明是要查询我们右外连接右表没有员工的部门号,过滤条件却为什么是左表员工表部门号为NULL的数据呢?它们是怎么知道这些NULL是右表哪个部门号记录的?
select dept.department_id
from employees emp right join departments dept
on emp.department_id = dept.department_id
where emp.department is null;
首先我们再次回忆一下关于执行顺序
1、FROM:先查看来自哪个表以及连接表
2、WHERE:先过滤掉不符合条件的数据,这样优化效率
3、SELECT:在过滤后的数据里找要查询的字段
4、ORDER…:进行其他的排序或分页等操作
通过上面我们了解了,原来FROM是先执行的,也就是说,这个时候是先执行的FROM,也就是emp和dept表的数据通过部门号先进行了全部数据的关联,也就是selectfrom emp+selectfrom dept的数据,可见第一步的记录数非常庞大,这里因为是右外连接,所以不满足连接条件的(也就是左表有记录没有department_id)数据也被列了出来,既然右表记录没有连接左表记录,那么拼接到一起的左表记录自然就都是NULL来替代,这里很关键,注意,右表不满足条件的记录中拼接在一起的左表记录数据全部由NULL替代
知道了上面,我们再看WHERE,这是大家最疑惑的地方了,为什么靠emp为空的部门id就能知道dept没有员工的部门号
我们说到了上面的FROM,现在where将庞大的数据列进行过滤,我们给出的是,左表部门号为空的数据,这个时候就去直接去找左表部门号为空的记录,别忘了,多表连接,两个表都是拼接在一起,没有就用NULL顶替,所以自然靠左表为NULL的数据就可以定位到右表有记录但是没有左表记录的右表记录了,这个时候你哪怕是用左边任何字段来当做IS NULL的过滤条件,都是可以查出来右表部门没有员工的记录的!
左外连接的结果集包含左表所有记录和右表中满足连接条件的记录,结果集那些不符合连接条件来源于右表列值为null,但是它们仍然拼接到了一起,左外有记录,右表全是null,通过右表数据是null的记录来定位左表有记录但是没有符合连接条件的左表记录
#UNION 和 UNION ALL的使用
#UNION会执行去重的操作
#UNION ALL不会执行去重的操作
#结论:如果明确知道合并数据后的结果数据不存在重复数据,或者不需要去除重复的数据
#则尽量使用UNION ALL语句,以提高数据查询的效率
#7种JOIN的实现
#第一种:内连接
SELECT employee_id,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;#106条
#第二种:左外连接查询
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`;#1
07条
#第三种:右外连接
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;#122条
#第四种:只要左外内容
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`#1条
WHERE d.`department_id` IS NULL;
#第五种:只要右外内容
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`#16条
WHERE e.`department_id` IS NULL;
#第六种:满外连接
#方式1:左外连接+右连接
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`#123条 107条
UNION ALL#它们的列属性个数必须一样
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`#123条 16条
WHERE e.`department_id` IS NULL;
#方式2:左连接+右外连接
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`#123条 1条
WHERE d.`department_id` IS NULL
UNION ALL
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`;#123条 122条
#第七种:左右连接
SELECT employee_id,department_name
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`#17条 1条
WHERE d.`department_id` IS NULL
UNION ALL#它们的列属性个数必须一样
SELECT employee_id,department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`#17条 16条
WHERE e.`department_id` IS NULL;
可以看到,没有什么难的,无非是单独查询出结果,然后将两个结果使用UNION ALL来进行拼接,来达到效果
NATURAL JOIN与USING的使用
自然连接


#SQL99语法的新特性1:自然连接
#这是正常的SQL99语法
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
AND e.`manager_id` = d.`manager_id`;
#这是新特性的自然连接形式
SELECT e.employee_id,e.last_name,d.department_name
#和上面的效果一致,不过这种新特性在实际开发中几乎没用
FROM employees e NATURAL JOIN departments d;
#SQL99语法的新特性2:USING
#这是正常的SQL99语法
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`;#106条
#这是新特性的替换连接条件的连接形式
SELECT employee_id,last_name,department_name
FROM employees e JOIN departments d
#有点像表级约束的样子,该情况只有两个表连接条件属性一样的时候才有用
#意义不大,尤其是自连接,是用不到的
#自连接:自己连接自己,比如:manager_id 管理者查询
USING(department_id);
我感觉吧,应该老老实实的用ON来进行条件连接,其他两个性特性的应用场景实在是太苛刻了,几乎没有什么实际的操作意义

在join on…join…on中可 join on…on…AND来达到连接条件拼接,但是还是建议join一个再加on,再join一个再加on,最好不要搞太多花哨的东西

附录

多表查询课后练习
#多表查询的课后练习
#1.查询所有员工的姓名,部门号和部门名称
SELECT e.last_name,e.department_id,d.department_name
FROM employees e LEFT OUTER JOIN departments d
ON e.`department_id` = d.`department_id`;
#2.查询90号部门员工的job_id和90号部门的location_id
#方法一
SELECT e.job_id,s.location_id
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
JOIN locations s
ON d.`location_id` = s.`location_id`
WHERE e.department_id = 90;
#方法二
SELECT e.job_id,d.`location_id`
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.department_id = 90;
#3.选择所有有奖金的员工的last_name,department_name,location_id,city
SELECT e.`commission_pct`,e.`last_name`,d.`department_name`,d.`location_id`,s.`city`
FROM employees e LEFT JOIN departments d
ON e.`department_id` = d.`department_id`
LEFT JOIN locations s
ON d.`location_id` = s.`location_id`
WHERE e.`commission_pct` IS NOT NULL;
SELECT*FROM
employees
WHERE employees.`commission_pct` IS NOT NULL;#35条记录
#4.选择city在Toronto工作的员工的last_name,job_id,department_id,department_name
SELECT e.`last_name`,e.`job_id`,d.`department_id`,d.`department_name`
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
JOIN locations s
ON d.`location_id` = s.`location_id`
WHERE s.`city` = 'Toronto';
#5.查询员工所在的部门名称、部门地址、姓名、工作、工资,其中员工所在的部门名称为'Executive'
SELECT d.`department_name`,s.`street_address`,s.`city`,e.`last_name`,e.`job_id`,e.`salary`
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
JOIN locations s
ON d.`location_id` = s.`location_id`
WHERE d.`department_name` = 'Executive';
#6.选择指定员工的姓名,员工号,以及它们的管理者的姓名和员工号,结果类似于下面的格式
#employees Emp manager Mar
#Kochhar 101 King 100
SELECT e1.`last_name` AS "employees",e1.`employee_id` AS "Emp",e2.`last_name` AS "manager",e2.`employee_id` AS "Mar"
FROM employees e1,employees e2
WHERE e1.`manager_id` = e2.`employee_id` AND e1.`last_name` = 'Kochhar';
#7.查询哪些部门没有员工
SELECT e.department_id,d.department_name
FROM employees e RIGHT JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE e.`department_id` IS NULL;
#8.查询哪个城市没有部门
SELECT d.department_name,d.department_id,s.`city`
FROM departments d RIGHT JOIN locations s
ON d.`location_id` = s.`location_id`
WHERE d.`location_id` IS NULL;
#9.查询部门名为Sales或IT的员工信息
SELECT e.`last_name`,e.`employee_id`
FROM employees e JOIN departments d
ON e.`department_id` = d.`department_id`
WHERE d.`department_name` = 'Sales' OR d.`department_name` = 'IT';
-----------------------------------------------
函数的分类

不同DBMS函数的差异

#该代码如果在Oracle的话下面是正常的拼接语句
#如果在MySQL则结果是0,表示MySQL没有识别出来内容
SELECT 'hello'||'world'
from DUAL;
#正确操作
SELECT CONCAT('hello','world')
from dual;
MySQL的内置函数及分类

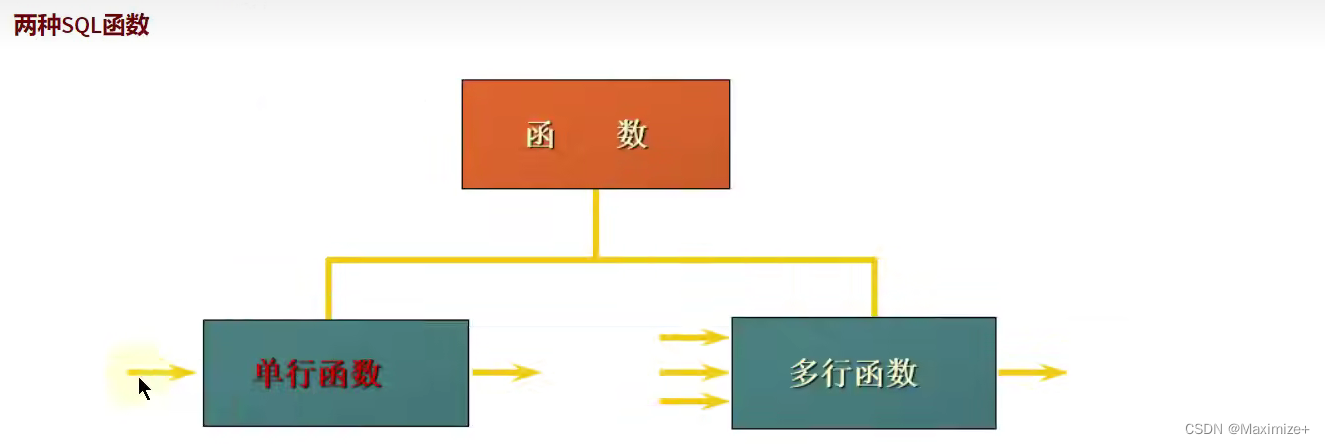

数值类型的函数讲解
基本函数
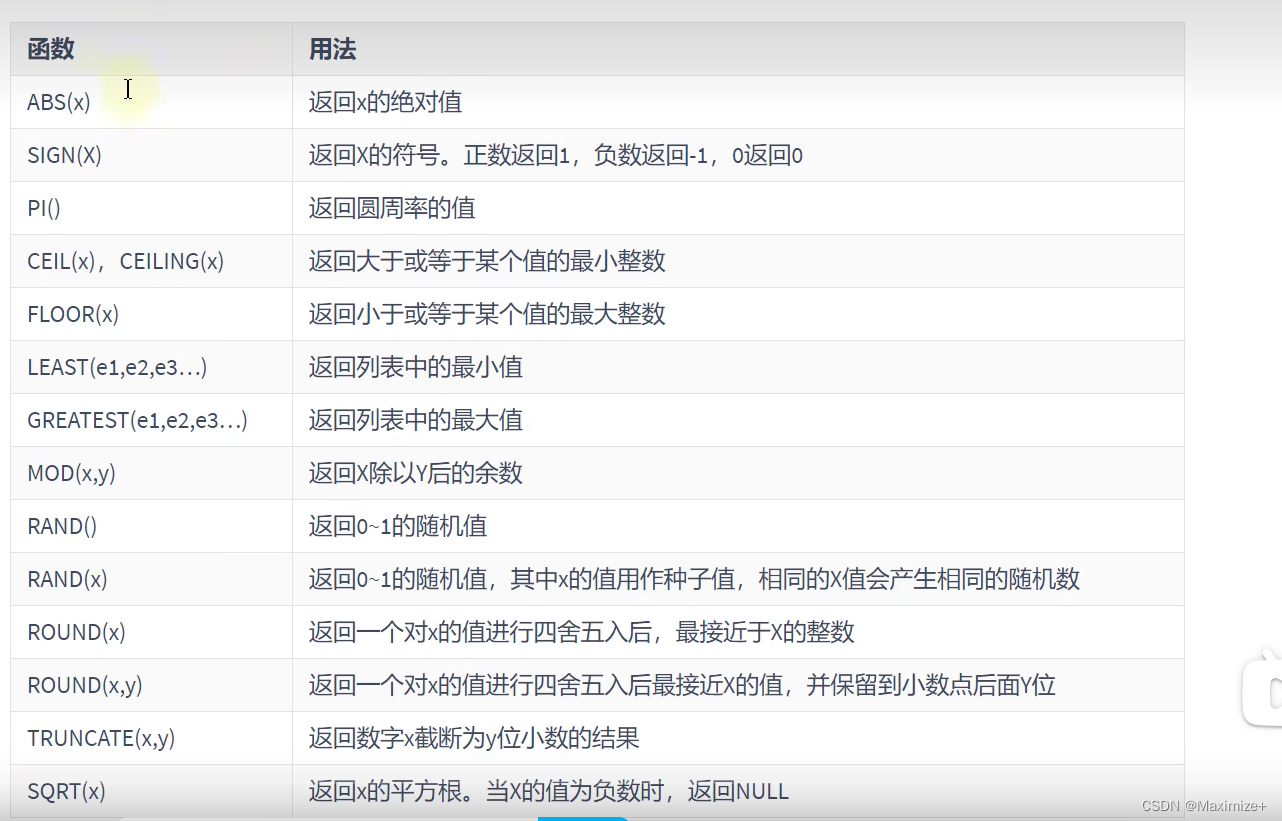
第一波
#单行函数
#数值函数-基本函数
SELECT ABS(-123),ABS(32),SIGN(-23),SIGN(43),PI(),CEIL(32.32),CEILING(-43.23),FLOOR(32.32),
FLOOR(-43.23),MOD(12,5)
FROM DUAL;
#随机数函数
SELECT RAND(),RAND(),RAND(10),RAND(10),RAND(-1),RAND(-1)
FROM DUAL;
#四舍五入,截断操作
SELECT ROUND(123.556),ROUND(123.456,0),ROUND(123.456,1),ROUND(123.456,2),ROUND(123.456,-1),ROUND(153.456,-2)
FROM DUAL;
#截断
#最少写0位,而且此处是没有四舍五入的
SELECT TRUNCATE(123.456,0),TRUNCATE(123.496,1),TRUNCATE(129.45,-1),ROUND(129.45,-1)
#并非是四射五六,9会直接变成0,写多少数0-9都是白扯 ,如果是ROUND就变成130了
FROM DUAL;
#单行函数可以嵌套
SELECT TRUNCATE(ROUND(123.456,2),0)#保留零位小数,此处会阶段,从123.0变123
FROM DUAL;
其实吧,我感觉上面的函数肯定还是没有任何难度的,只是这些功能你单纯在MySQL里可能会用到这些数据处理形式的函数,但是实际上Java的那些框架和层肯定会把数据处理好,而且明确性也远比这些函数好用,所以这里了解就行了,哪怕以后真的忘了,自己去百度百度或者翻阅资料就行了,相信哪个时候的水平,看看这些和喝凉水一样普通
第二波
第二波是一大堆数学函数,这个怎么说呢,本人数学水平有限,而且后续到数据结构的时候才会对数学进行钻研,所以我也是现在先了解下,不着急掌握,看看就好了,初学者根本没有必要去死磕这块内容的,数学虽然确实重要,但是用到的场景也是较少的
数学和三角函数
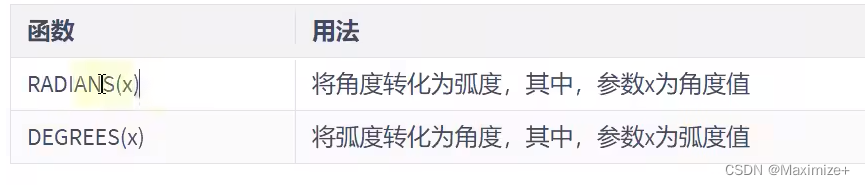
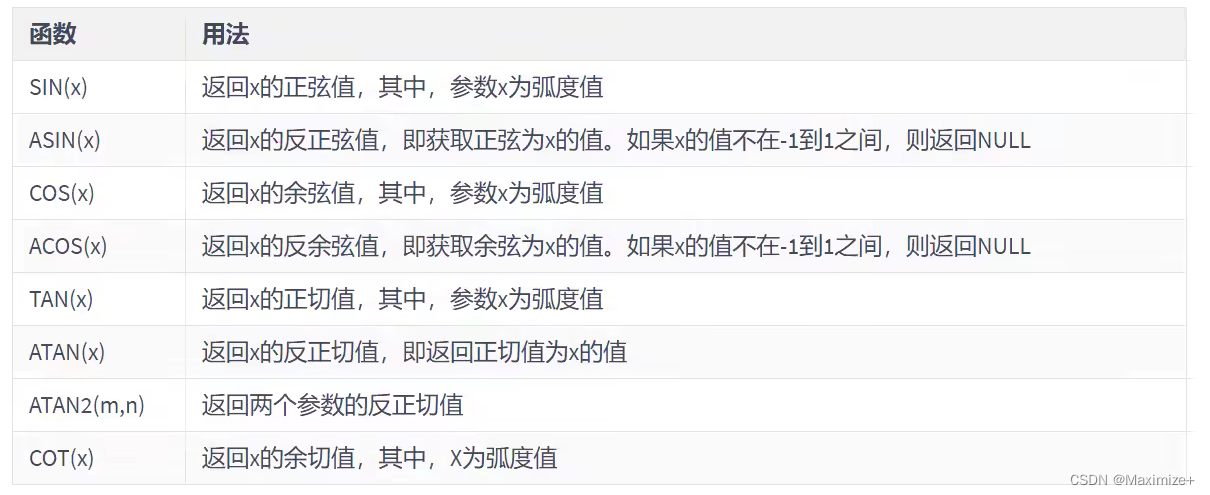
这个函数比较吃数学功底了,了解了解就行了
#数学函数和三角函数
#角度与弧度的互换
SELECT RADIANS(30),RADIANS(45),RADIANS(60),RADIANS(90),
DEGREES(2*PI()),DEGREES(RADIANS(60))
FROM DUAL;
#三角函数
#弧度值 角度变弧度
SELECT SIN(RADIANS(30)),DEGREES(ASIN(1)),#正弦取值角度
TAN(RADIANS(45)),#弧度值,接近一
DEGREES(ATAN(1))
FROM DUAL;
指数与对数

#指数和对数
#指数
#2的五次方,2的四次方
#EXP:以E为底,几次幂???
SELECT POW(2,5),POW(2,4),EXP(2)
FROM DUAL;
#对数
SELECT LN(EXP(2)),LOG(EXP(2))
FROM DUAL;
进制间的转换
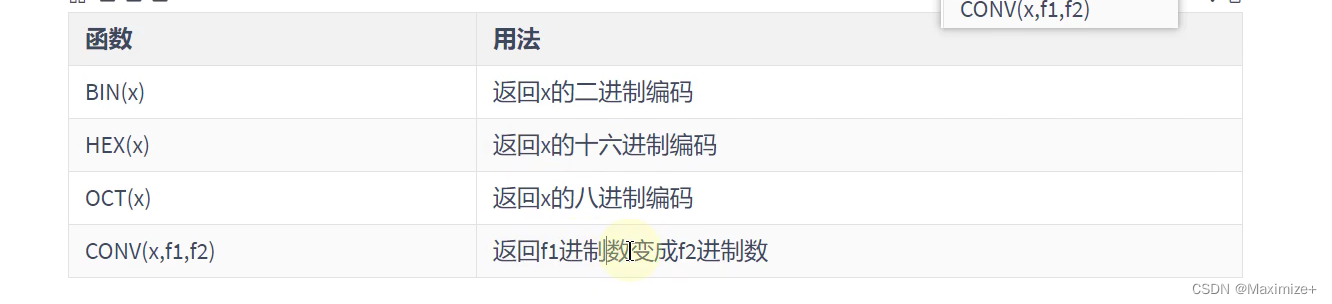
#进制间的转换
SELECT BIN(10),#查看十进制的数转换为二进制
HEX(10),#查看十进制的数转换为十六进制
OCT(10),#八进制
CONV(10,2,8)#表示10的数是2进制,然后转换为8进制
FROM DUAL;
字符串函数
由于函数量是真的大,我们以分波的形式来展现
第一波

#字符串函数
SELECT ASCII('abc'),#只和第一个字符有关系,大A表示65
#CHAR_LENGTH表示想要获取的字符个数,LENGTH则表示我们想要的字节数 一个汉字=3个字节
CHAR_LENGTH('HELLO'),CHAR_LENGTH('我们'),
LENGTH('HELLO'),LENGTH('我们')
FROM DUAL;
#CONCAT表示字符串连接
#xxx worked for yyy
SELECT CONCAT(e1.last_name,'worked for ',e2.last_name)
FROM employees e1 JOIN employees e2
ON e1.`manager_id` = e2.`employee_id`;
#这个函数表示连接,第一个 - 参数表示是定义的分隔符
#后面的参数就是自己定义的参数了,每次的逗号都会作为分隔标识
#此处会用-来作为分隔
SELECT CONCAT_WS('-','hello','mysql')
FROM DUAL;
#字符串是从1开始的
#所以这里是从第第二个开始,替换三个字符,替换内容为superM(newStr)
SELECT INSERT('hello',2,3,'superM'),#结果应该为 hsuperMo
REPLACE('hello','ll','mm'),#字符序列替换
REPLACE('hello','lol','mmm')#找不到,就不替换了,不会报错,保持原有str(字符串别名)
FROM DUAL;
#大小写转换
SELECT UPPER('hello'),LOWER('HelLo')
FROM DUAL;
SELECT last_name,salary
FROM employees
WHERE last_name = LOWER('king');#都变成小写 加不加意义不大 不严谨性
#类似于Java那个subString,
SELECT LEFT('hello',2),RIGHT('hello',3),RIGHT('hello',13)#如果取值大于了字符串长度,将会全部取出字符串内容
FROM DUAL;
#从左边补位
SELECT e.`employee_id`,e.`last_name`,LPAD(salary,10,'*')#十位,不够就从左到右补充*号
FROM employees e;
#24000.00 -> 8位,要求10位 = **24000.00
#从右边补位
SELECT e.`employee_id`,e.`last_name`,RPAD(salary,10,'*')#十位,不够就从左到右补充*号
FROM employees e;
#24000.00 -> 8位,要求10位 = 24000.00**
#它们的最终目的都是对齐
#LPAD:左对齐 RPAD:右对齐
第二波


#exp1,exp2...是数据库函数里参数顺序的意思,可能不严谨,此处以这样的形式来说明参数位置
#第二波函数
SELECT CONCAT('---',TRIM(' h el lo '),'***')#去除字符串首位空格
FROM DUAL;
#去除左边空格
SELECT CONCAT('---',LTRIM(' h el lo '),'***')#去除字符串首位空格
FROM DUAL;
#去除右边空格
SELECT CONCAT('---',RTRIM(' h el lo '),'***')#去除字符串首位空格
FROM DUAL;
#重复字符串内容
SELECT REPEAT('hello',4)
FROM DUAL;
#返回n个空格
SELECT REPEAT('hello',4),LENGTH(SPACE(5))#提供了5个空格
FROM DUAL;
#比较字符串1和2的ASCII码值的大小
#abcde...数值逐渐增大,所以abe是比abc的ASCII码值要大的 返回-1 如果小返回1 如果等于返回0 其他返回null
SELECT REPEAT('hello',4),LENGTH(SPACE(5)),STRCMP('abc','abe')
FROM DUAL;
#返回字符串index位置的len个字符
SELECT SUBSTR('hello',2,2)#从1开始的 就是h el lo 去el el -> 23[lenIndex] -> 12[index]
FROM DUAL;
#返回目标字符串在选择字符串首次出现的位置
SELECT LOCATE('l','hello')#exp1是子字符串[目标字符串],exp2是父字符串[选择字符串]
FROM DUAL;
#返回exp1对应数的对应值
SELECT ELT(3,'a','b','c','d')
FROM DUAL;
#返回exp1在N个字符串列表里第一次出现的位置
SELECT FIELD('mm','gg','jj','mm','dd','mm')
FROM DUAL;
#返回exp1在exp2中出现的位置,其中exp2是一个被逗号分隔的字符串
SELECT FIND_IN_SET('jj','mm,dd,kk,jj,ll')#这里仍然是从1开始算的,字符串都是1开始
FROM DUAL;
#比较两个字符串,如果exp1和exp2相等
SELECT NULLIF('hello','hello'),NULLIF('hello','helol')
FROM DUAL;
第二波的函数大多数都是字符串索引和内容替换、内容查找、内容大小等对比和操作
日期和时间函数
获取日期、时间
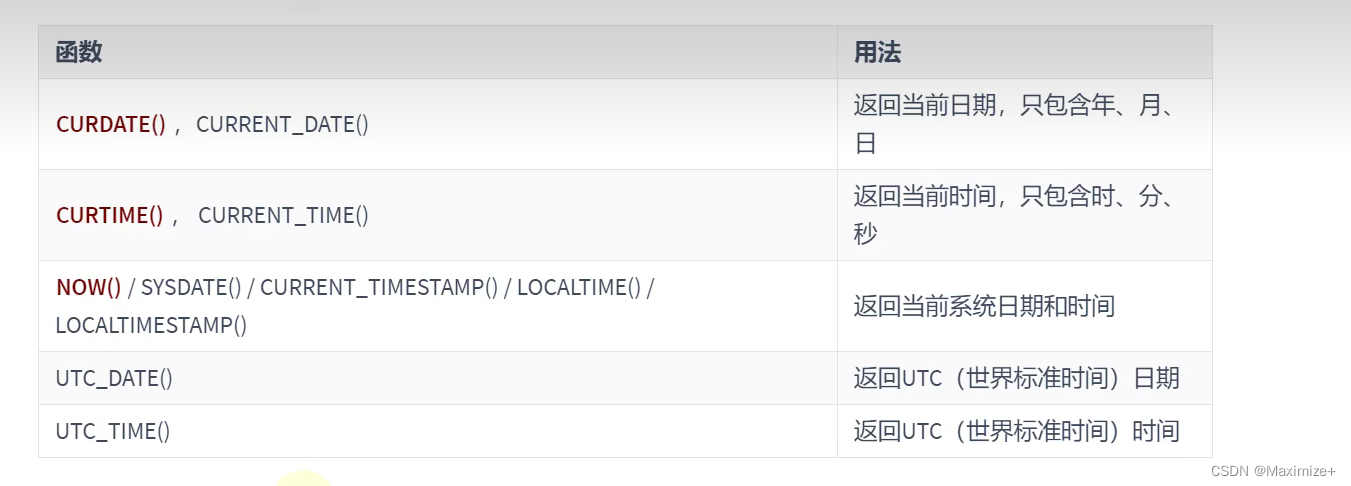
#日期和时间函数
#获取日期、时间
SELECT CURDATE(),CURRENT_DATE(),CURTIME(),NOW(),SYSDATE(),
UTC_DATE(),UTC_TIME()
FROM DUAL;
日期与时间戳的转换

#日期与时间戳的转换
SELECT UNIX_TIMESTAMP(),#获得当前系统毫秒数
UNIX_TIMESTAMP('2024-7-1 12:12:12'),
FROM_UNIXTIME(1668825449),#转换为日期时间格式
FROM_UNIXTIME(1719807132)
FROM DUAL;
获取月份、星期、星期数、天数等函数
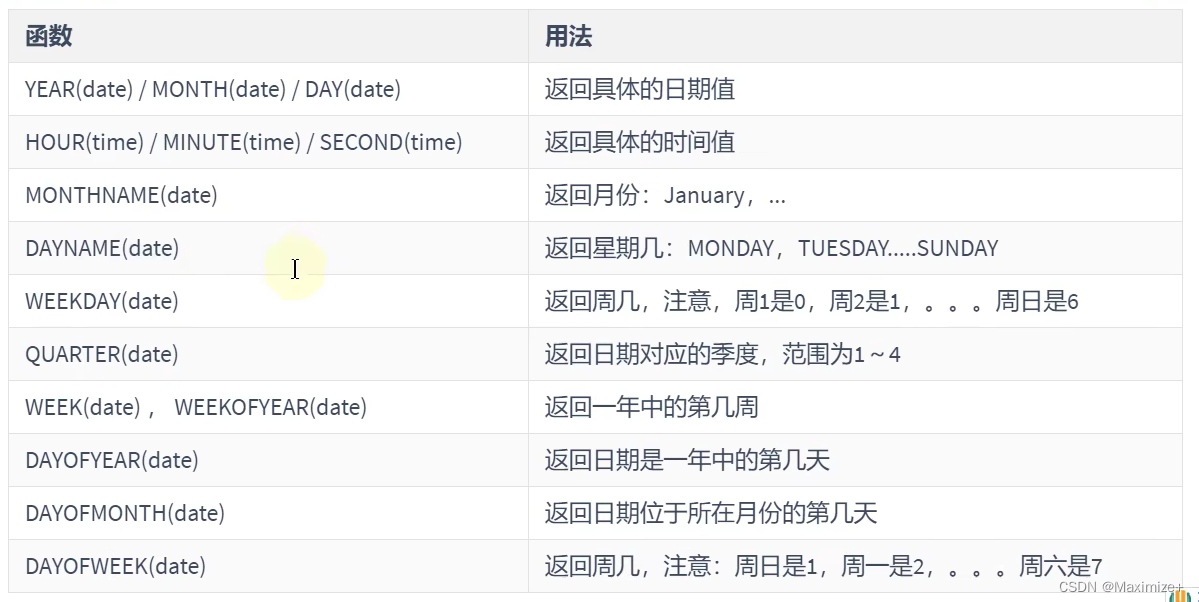
#获取月份、星期、星期数、天数等函数
#年、月、日、小时、分钟、秒
SELECT YEAR(NOW()),MONTH(NOW()),DAY(NOW()),
HOUR(NOW()),MINUTE(NOW()),SECOND(SYSDATE())
FROM DUAL;
SELECT MONTHNAME('2021-10-26'),DAYNAME('2021-10-26'),WEEKDAY('2021-10-26'),
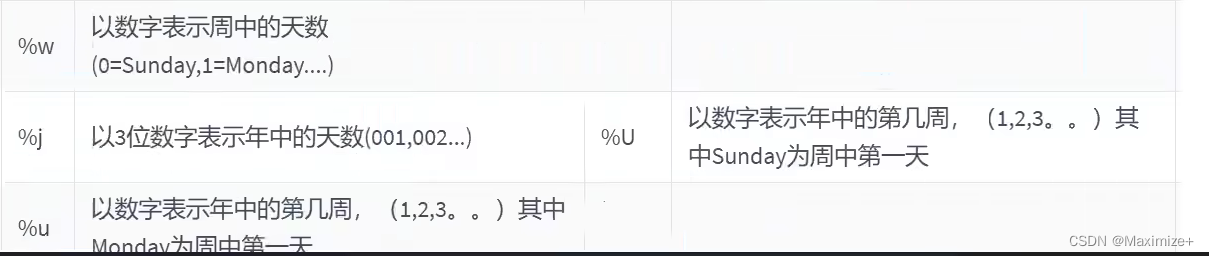
QUARTER(NOW()),WEEK(NOW()),DAYOFYEAR(NOW()),
DAYOFMONTH(NOW()),DAYOFWEEK(NOW())
FROM DUAL;
日期操作函数

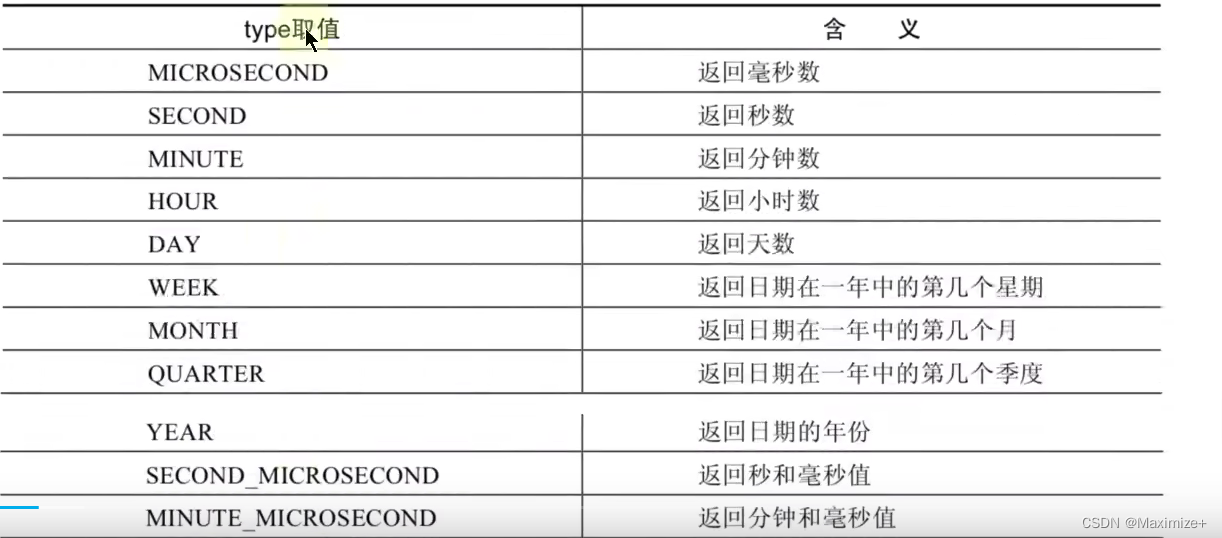
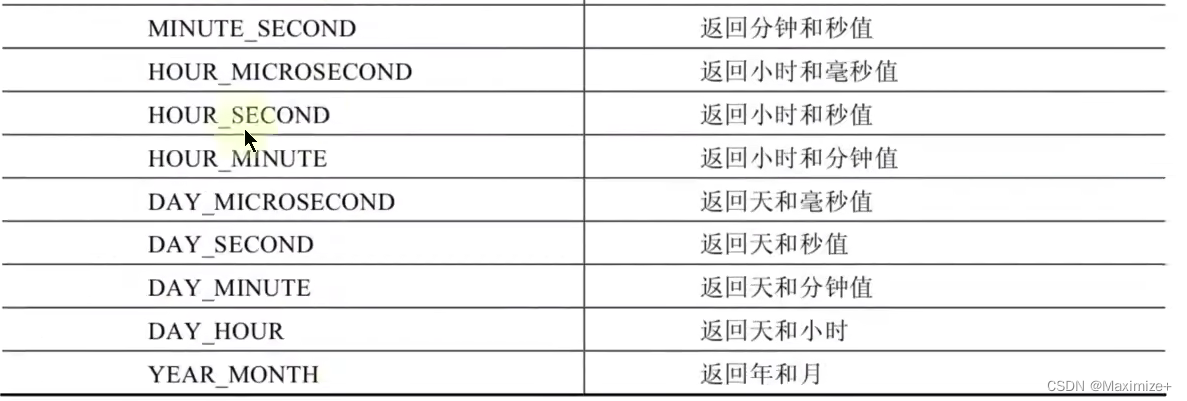
#日期操作函数
SELECT EXTRACT(SECOND FROM NOW()),#获取当前秒数
#获取当前日;获取当前小时和秒值
EXTRACT(DAY FROM NOW()),EXTRACT(HOUR_MINUTE FROM NOW())
FROM DUAL
时间和秒钟转换的函数

#时间和秒钟转换的函数
SELECT TIME_TO_SEC(CURTIME()),TIME_TO_SEC(NOW()),
SEC_TO_TIME(39276)
FROM DUAL;
计算日期和时间的函数

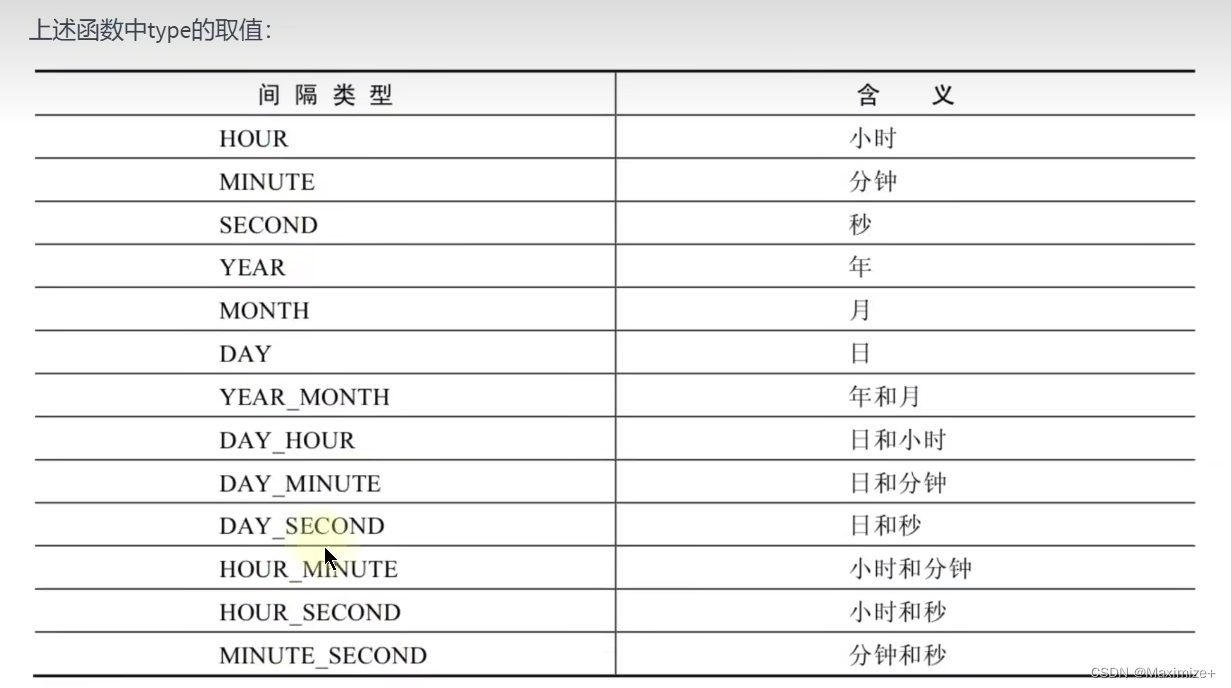
#计算日期和时间的函数
#第一组
SELECT NOW(),DATE_ADD(NOW(),INTERVAL 1 YEAR),#在现有的年份上加了一年
DATE_ADD(NOW(),INTERVAL -10 YEAR),#在现有的年份上减了十年
DATE_SUB(NOW(),INTERVAL 10 YEAR)#减了十年
FROM DUAL;
SELECT DATE_ADD('2020-10-10 10:10:10',INTERVAL '1_1' MINUTE_SECOND),
DATE_ADD('2020-10-10 10:10:10',INTERVAL 1 YEAR)
FROM DUAL;
第二组
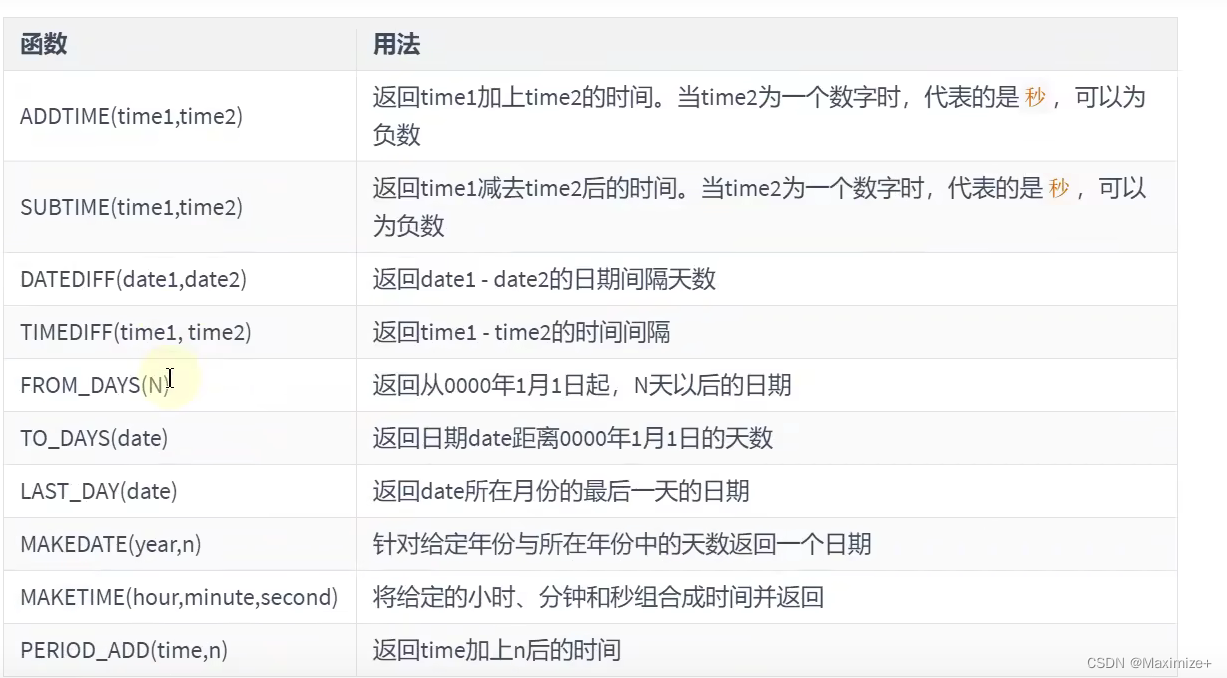
SELECT ADDTIME(NOW(),20),SUBTIME(NOW(),30),SUBTIME(NOW(),'1:1:3'),DATEDIFF(NOW(),'2021-10-01'),
DATEDIFF(NOW(),'2021-10-25 22:10:10'),FROM_DAYS(366),TO_DAYS('0000-12-25'),
TO_DAYS(NOW()),MAKEDATE(YEAR(NOW()),12),MAKETIME(10,21,23),
PERIOD_ADD(2020010101,10)
FROM DUAL;
日期的格式化与解析
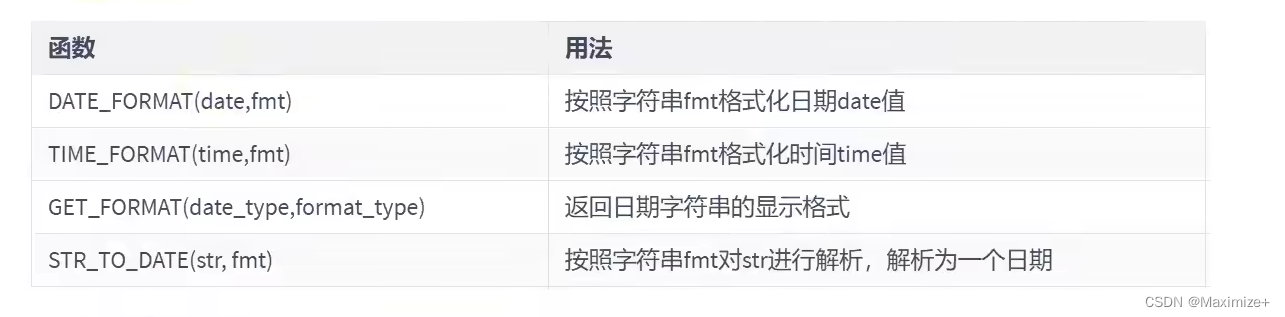

#日期和时间的格式化和解析
#格式化:日期 --->字符串
#解析:字符串 --->字符串
#此时我们谈的是日期的显示格式化和解析
#之前,我们接触过隐式的格式化或解析
SELECT*
FROM employees
WHERE hire_date = '1993-01-13';
#格式化:
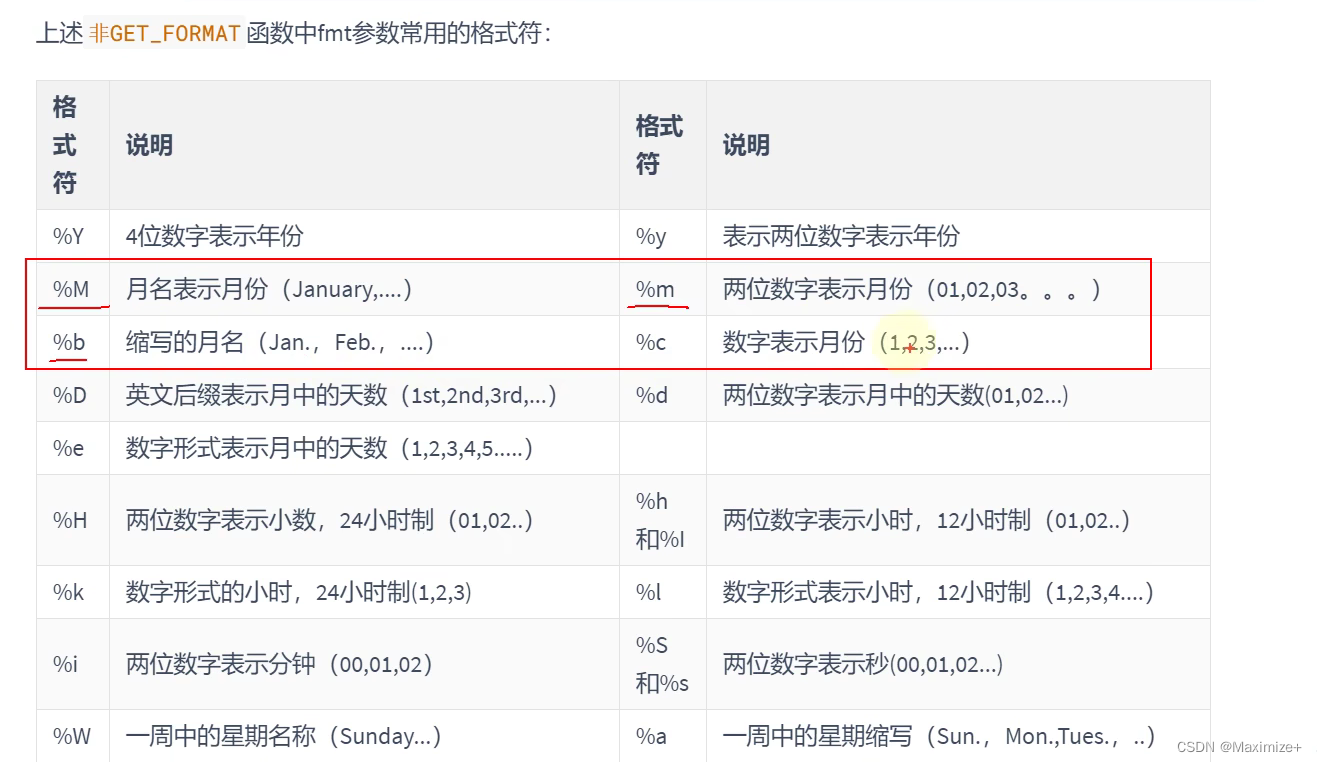
SELECT DATE_FORMAT(NOW(),'%Y-%M-%D'),
DATE_FORMAT(NOW(),'%y-%m-%d'),#标准年月日
TIME_FORMAT(NOW(),'%H:%i:%S'),DATE_FORMAT(NOW(),'%Y-%M-%D %h:%i:%S %W %T %r')
FROM DUAL;
#格式化的逆过程
SELECT STR_TO_DATE('2022-November-19th 11:42:18 Saturday 11:42:18 11:42:18 AM','%Y-%M-%D %h:%i:%S %W %T %r');
FROM DUAL;
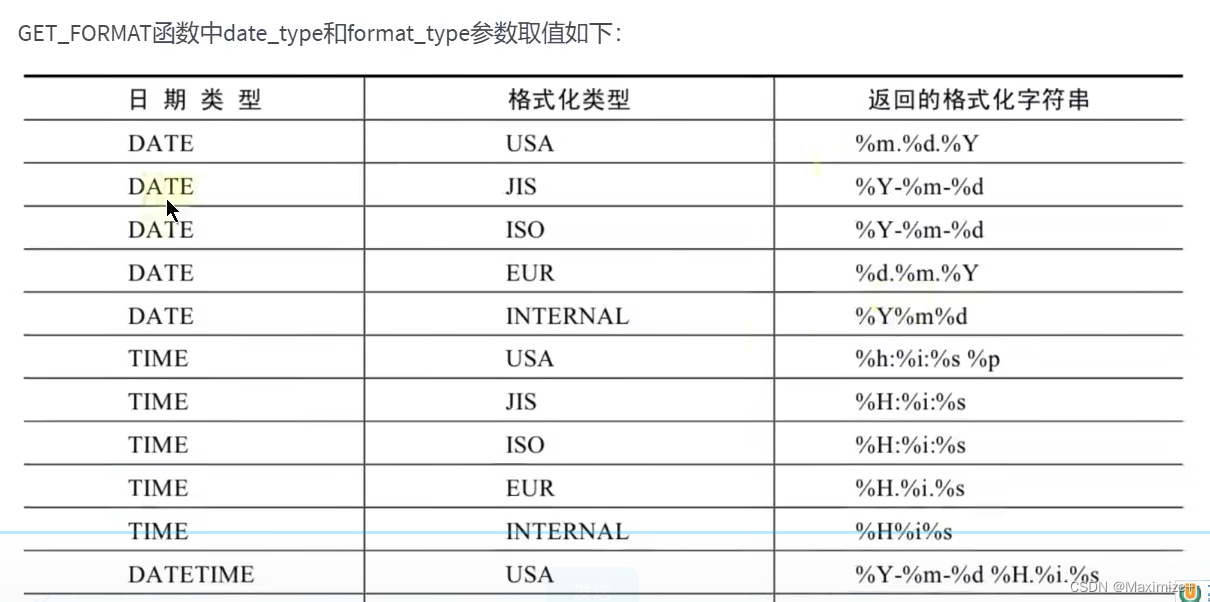
SELECT DATE_FORMAT(NOW(),GET_FORMAT(DATE,'USA'))
FROM DUAL;#美国表达年月日的样子
流程控制函数讲解
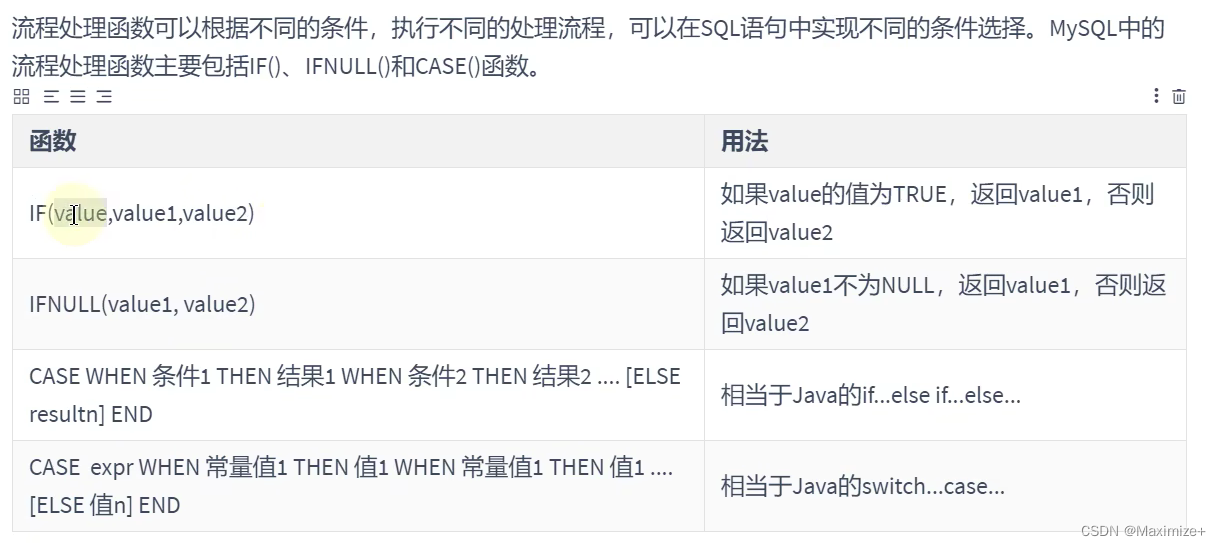
#流程控制函数
#IF(VALUE,VALUE1,VALUE2)
SELECT last_name,salary,IF(salary>=6000,'高工资','低工资')
FROM employees;
SELECT last_name,commission_pct,IF(commission_pct IS NOT NULL,commission_pct,0) "details",
salary*12*(1+IF(commission_pct IS NOT NULL,commission_pct,0)) "annual_sal"
FROM employees;
#IFNULL(VALUE1,VALUE2):看作是IF(VALUE,VALUE1,VALUE2)的特殊情况
SELECT last_name,commission_pct,IFNULL(commission_pct,0) "details"
FROM employees;
#CASE WHEN ... THEN ... WHEN ... THEN ... ELES ...
#类似于Java的IF ... ELSE IF ... ELSE IF ... ELSE ...
SELECT last_name,salary,CASE WHEN salary >= 15000 THEN '白骨精'
WHEN salary >= 10000 THEN '潜力股'
WHEN salary >= 8000 THEN '赤伶'
ELSE '学生' END AS "details",department_id
FROM employees;
#CASE ... WHEN ... THEN ... WHEN ... THEN ...ELSE ... END
/*
查询部门号为10,20,30的员工信息
若部门号为10,则打印其工资的1.1倍,20号部门,则打印其工资的1.2倍
30号部门打印其工资的1.3倍,其他部门打印1.4倍
*/
SELECT last_name,salary,department_id,CASE WHEN department_id = 10 THEN (salary*1.1)
WHEN department_id = 20 THEN (salary*1.2)
WHEN department_id = 30 THEN (salary*1.3)
ELSE salary*1.4
END AS "details"
FROM employees;
MySQL信息函数等讲解
加密与解密函数
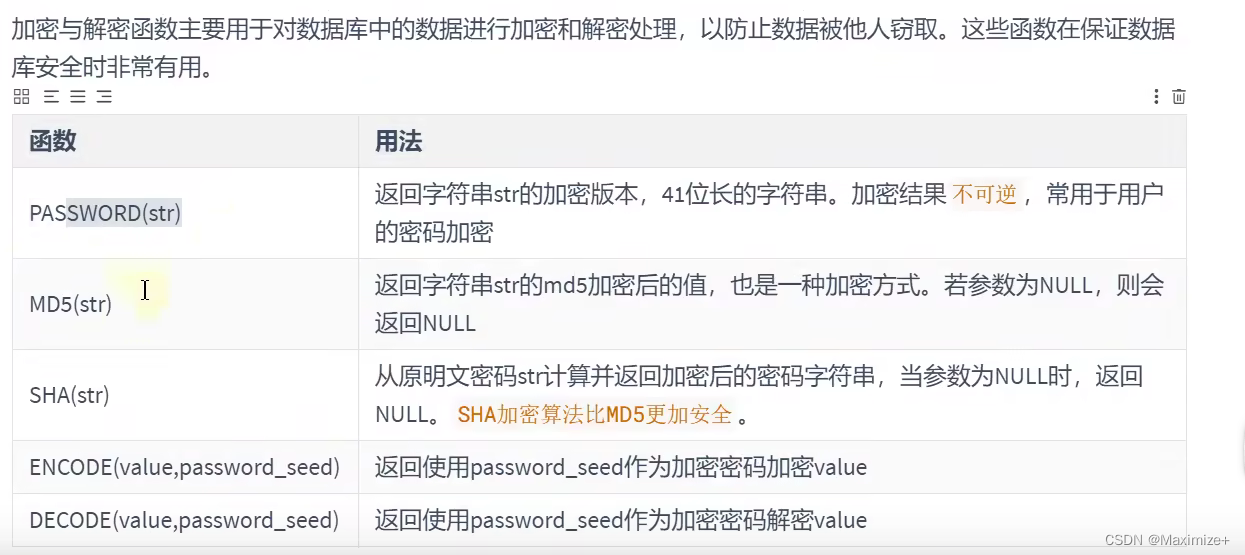
#加密与解密的函数
SELECT PASSWORD('mysql'),SHA('mysql'),MD5(MD5('mysql'))#MySQL8.0不推荐使用了,5.7是可以用的
FROM DUAL;
#ENCODE()\DECODE()也弃用了
SELECT ENCODE('atguigu','mysql')
FROM DUAL;
信息函数
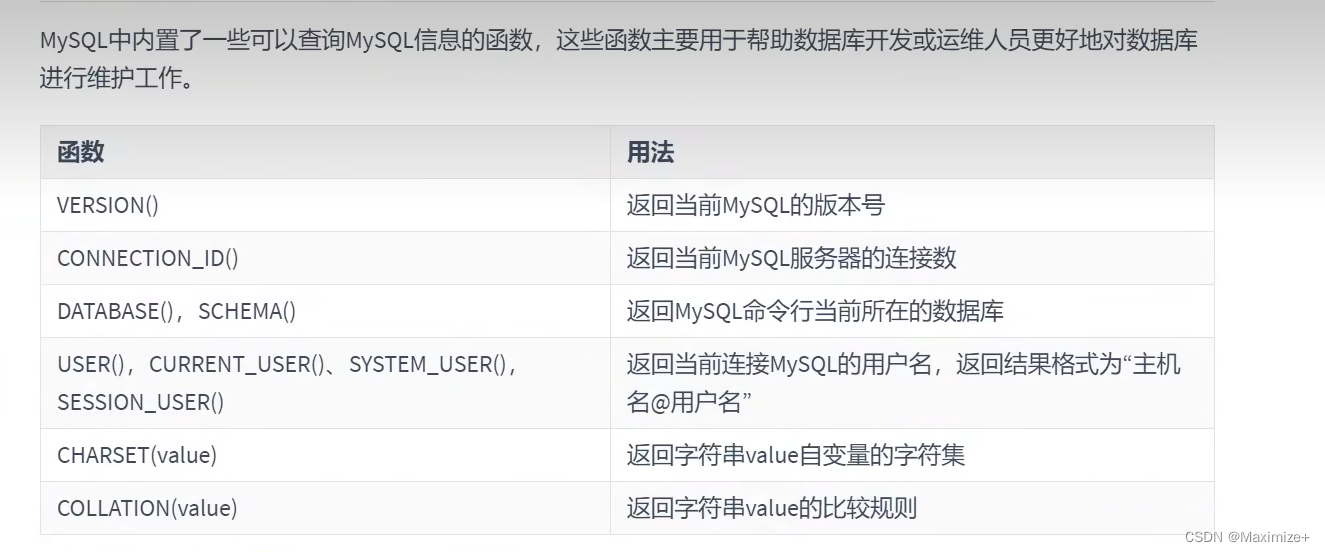
#MySQL信息函数
SELECT VERSION(),CONNECTION_ID(),DATABASE(),SCHEMA(),
USER(),CURRENT_USER(),CHARSET('尚硅谷'),COLLATION('尚硅谷')
FROM DUAL;
其他函数
#7.其他函数
#保留两位小数
#如果n的值小于或等于0,则只保留整数部分
SELECT FORMAT(123.123,2),FORMAT(123.123,0),FORMAT(123.123,-2)
FROM DUAL;
SELECT CONV(10,10,2),CONV(8888,10,16),CONV(NULL,10,2)
FROM DUAL;
SELECT INET_ATON('192.168.1.100'),INET_NTOA(3232235876)
FROM DUAL;
#将表达式执行N次,主要测试所耗时间
SELECT BENCHMARK(1,MD5('mysql'))
FROM DUAL;
#将value所使用的编码修改为exp2指定的编码
#CONVERT()可以实现字符集的转换
SELECT CHARSET('atguigu'),CONVERT('atguigu' USING 'utf8mb4'),CHARSET(CONVERT('atguigu' USING 'utf8mb4')),#4个字节来表示一个字符
CHARSET(CONVERT('atguigu' USING 'gbk'))
FROM DUAL;
单行函数练习
#单行函数练习
#1.显示系统时间(注:日期+时间)
SELECT NOW(),CURDATE(),CURRENT_TIMESTAMP(),LOCALTIME()
FROM DUAL;
#2.查询员工号,姓名,工资,以及工资提高百分之20%的结果(new salary)
SELECT e.`employee_id`,e.`last_name`,e.salary,e.salary*1.2 AS "new salary"
FROM employees e;
#3.将员工的姓名按首字母排序,并写出姓名的长度(length)
SELECT e.`last_name`,LENGTH(e.`last_name`) 'name_length'
FROM employees e
#ORDER BY e.`last_name` ASC;
ORDER BY name_length ASC;
#4.查询员工id,last_name,salary,并作为一个列输出,别名为OUT_PUT
SELECT CONCAT_WS('-',e.`employee_id`,e.`last_name`,e.`salary`)AS "OUT_PUT"
FROM employees e;#MySQL并不区分数据表的大小写
#5.查询公司各员工工作的年数、工作的天数,并按工作年数的降序排序
SELECT e.last_name,e.`employee_id`,e.`hire_date`,DATEDIFF(NOW(),e.`hire_date`)/365 AS "worked_years",
DATEDIFF(NOW(),e.`hire_date`) AS "worked_days"
FROM employees e
ORDER BY worked_years DESC;
#6.查询员工姓名,hire_date,department_id,满足以下条件:雇佣时间在1997年之后,department_id为80或90或110或commission_pct不为空
SELECT e.`last_name`,e.`hire_date`,e.`department_id`,e.`commission_pct`
FROM employees e
#这里的日期时间运算存在隐式转换
WHERE commission_pct IS NOT NULL
AND e.`department_id` IN(80,90,110)
#AND e.`hire_date` >= '1997-1-1';
AND DATE_FORMAT(e.`hire_date`,'%Y-%m-%d')>='1997-01-01';#显示转换,格式化:日期--->字符串
#7.查询公司中入职超过10000天的员工姓名、入职时间
SELECT last_name,hire_date
FROM employees
WHERE DATEDIFF(CURDATE(),hire_date)>=10000;
#8.做一个查询,产生以下结果
#<last_name>erans<salary>mothly but wants <salary*3>
SELECT CONCAT_WS('-',last_name,'earns',TRUNCATE(salary,0),'mothly but wants',TRUNCATE(salary*3,0)) "Dream Salary"
FROM employees;
#9.使用case-when,按照下面的条件
/*job grade
AD_PRES A
ST_MAN B
IT_PROG C
SA_REP D
ST_CLERK E
*/
SELECT e.last_name,e.`job_id`,CASE WHEN e.job_id = 'AD_PRES' THEN 'A'
WHEN e.job_id = 'ST_MAN' THEN 'B'
WHEN e.job_id = 'IT_PROG' THEN 'C'
WHEN e.job_id = 'SA_REP' THEN 'D'
WHEN e.job_id = 'ST_CLERK' THEN 'E'
ELSE '无特殊'
END AS "job_name"
FROM employees e;
内容风格更换通知
后面的代码比如分组查询和子查询以及像存储过程和视图这些内容,都并不难,不过需要很多文字来描述和概括,是比较偏向理论的内容,其他的内容的介绍和代码占比大概为 (文字内容)65%/(代码内容)35%
五大常用聚合函数
聚合函数(聚集、分组),它对一组数据进行汇总的函数,输入的是一组数据的集合,输出的是单个值


#聚合函数
#1.常见的几个聚合函数
#AVG/SUM:只适用于数值类型的字段(或变量)
SELECT AVG(salary),SUM(salary),AVG(salary)*107
FROM employees;
#如下操作是没有任何意义的
SELECT SUM(last_name),AVG(last_name),SUM(hire_date)#无法计算 返回0,就像1+'a'的返回值一样
FROM employees;
#MAX/MIN:适用于数值类型、字符串类型、日期时间类型的字段(或变量)
SELECT MAX(salary),MIN(salary)
FROM employees;
SELECT MAX(last_name),MIN(last_name),MAX(hire_date),MIN(hire_date)#按照a-z的位数排列 z最大 a最小 多行结果返回一行结果->聚合函数
FROM employees;
#COUNT
#方式1:CONT(*)
#方式2:CONT(1)
#方法2:CONT(具体字段) -> 不一定对
#该聚合行数在模拟开发中挺常用的,比如返回订单数量,或者返回用户条数数量
#根据字段来进行统计,null不加入计算
SELECT #该内容在JDBC语法中,用的挺多的,比如返回一个表中字段所出现的字段
COUNT(employee_id),COUNT(salary),
#还比较常用的就是返回单个记录行数,其他的就是指定返回等等
COUNT(1),#这里其实是常数形式
COUNT(*),
COUNT(commission_pct)#如果出现了多个一起查询的数据,会发现上面的null就也变成了107条,而非35
#因为是其他记录相当于变成了常数参与在了一起查询,所以尽管是NULL,仍然还是统计上了,所以这种情况一定要分开写
#计算表中有多少条记录,和SELECT*FROM employees 本质相同
FROM employees;SELECT commission_pct FROM employees WHERE commission_pct IS NOT NULL;#35条 107-35=null列个数
SELECT COUNT(commission_pct)#35(没有统计NULL)
FROM employees;
#公式:AVG = SUM/COUNT
SELECT AVG(salary),SUM(salary)/COUNT(salary),#不要写死,这样很不灵活,通过COUNT(具体字段)来实现动态同步计算
AVG(commission_pct),SUM(commission_pct)/COUNT(commission_pct),SUM(commission_pct)/107
FROM employees;
#需求:查询公司中平均奖金率
#错误的!
SELECT AVG(e.`commission_pct`)
FROM employees e;
#IFNULL(exp1,exp2):如果数值(使用的是exp1)为NULL,使用exp2的值,如果不为NULL使用exp1值
SELECT AVG(e.`commission_pct`)/COUNT(IFNULL(commission_pct,0))
FROM employees e;
#求方差、标准差、中位差
GROUP BY
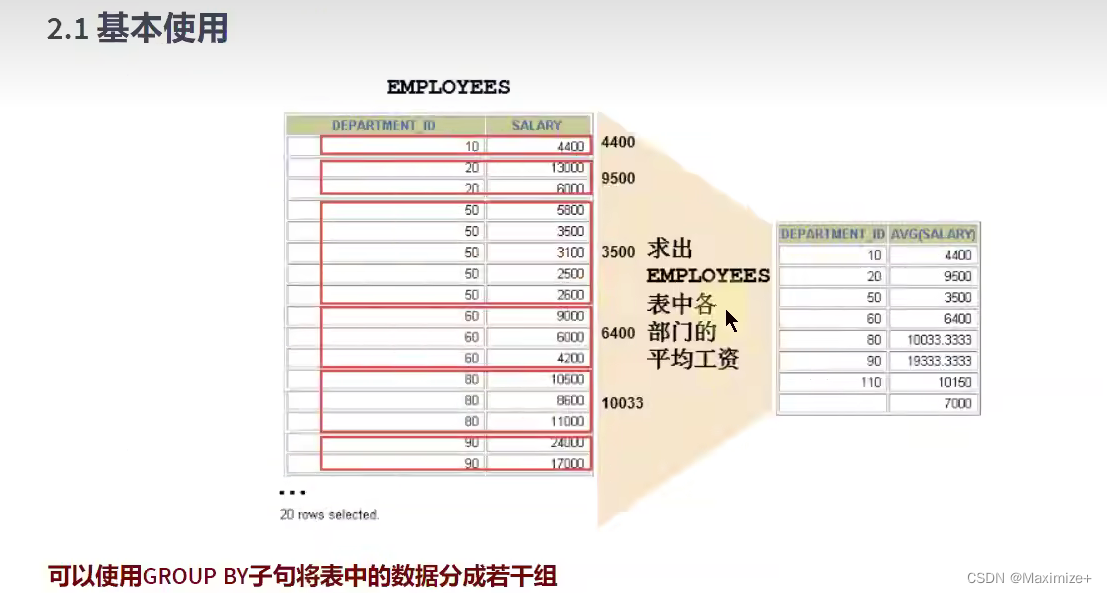
基本使用
#如何需要统计表中的记录数,使用COUNT(*)、COUNT(1),COUNT(filed)
#哪个效率更高呢?
#如果使用的是MyISAM存储引擎,则三者效率相同。都是O(1)
#如果使用的是InnoDB存储引擎,则三者效率不一样:*>1>FILED
#-------------------------------------------------------------------------
#2.GROUP BY 的使用
#需求:查询各个部门的平均工资,最高工资
SELECT e.`department_id`,AVG(e.`salary`),MAX(salary)
FROM employees e
GROUP BY e.`department_id`;
#需求:查询各个job_id的平均工资
SELECT job_id,AVG(salary)
FROM employees
GROUP BY job_id;
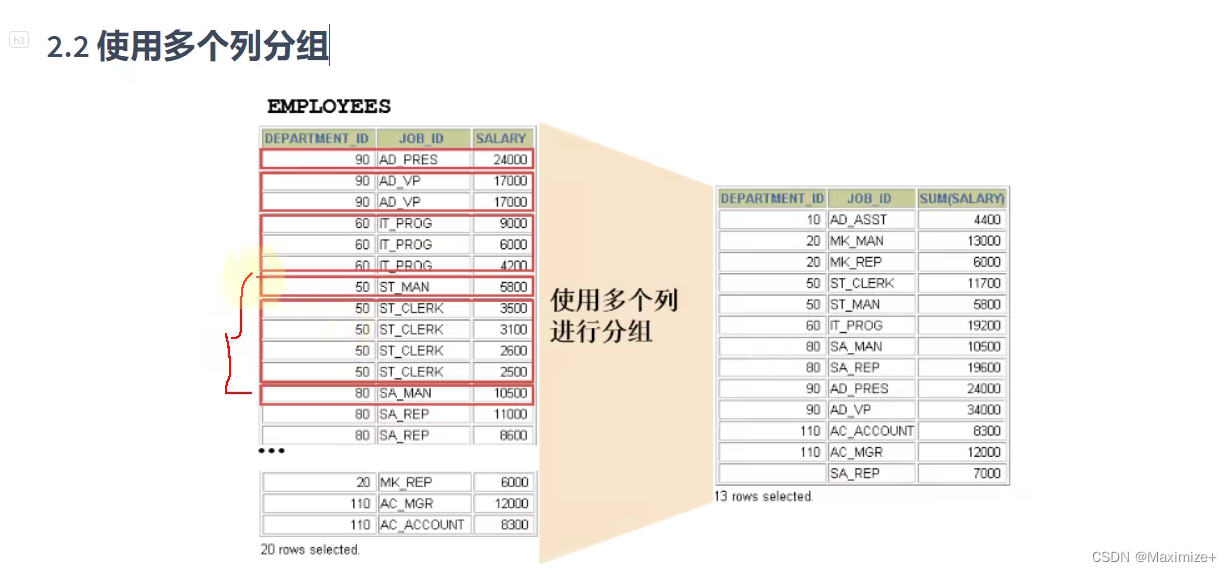
使用多个列分组
#需求:查询各个department_id,job_id的平均id
SELECT department_id,job_id,AVG(salary)
FROM employees
#按照部门分,然后再按照部门里每个工种分
#有点类似于排序的一级、二级...
GROUP BY department_id,job_id;
SELECT department_id,job_id,AVG(salary)
FROM employees
#按照部门分,然后再按照部门里每个工种分
#有点类似于排序的一级、二级...
#这就和小学学的那些运算法则似的,积是两个因数相乘得到的,因素的顺序调换是不影响结果的 2X3 = 3X2
GROUP BY job_id,department_id;#谁前谁后没有什么区别
#错误的,能执行成功,但是并没有意义,是错误的
#如果只是筛选了部门id,那么查询的job_id和工资要怎么显示呢?
#因为一个部门里是有多个job_id的
SELECT department_id,job_id,AVG(salary)
FROM employees
GROUP BY department_id;#结果不对,查询条件不精确
#结论1:SELECT中出现的非组函数的字段必须声明在GROUP BY中
#反之GROUP BY中声明的字段不一定需要在SELECT中
#结论2:GROUP BY声明在FROM后面、WHERE后面,ORDER BY前面、LIMIT前面
新特性

#结论3:MySQL中GROUP BY中使用WITH ROLLUP
SELECT department_id,AVG(salary)
FROM employees#各个部门的平均工资 -> 12组
GROUP BY department_id WITH ROLLUP;#代表所有平均工资 ,多了该字段的总平均字段
#需求:查询各个部门的平均工资
#结合排序使用
SELECT department_id,AVG(salary)AS "avg_salary"
FROM employees#各个部门的平均工资 -> 12组
GROUP BY department_id
ORDER BY avg_salary DESC;
#有了WITH ROLLUP的话要慎重和排序结合使用
SELECT department_id,AVG(salary)
FROM employees#各个部门的平均工资 -> 12组
GROUP BY department_id WITH ROLLUP
ORDER BY avg_salary DESC;#直接报错了,多的一行也会进行排序,但是这是公司的数据
#说明:当使用ROLLUP时,不能使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的
HAVING的使用与SQL语句的执行过程
该小节是基于除子查询外,目前的全部查询结构,很重要,了解了该过程才能在出错时不迷糊以及可以把控好流程
其实子查询也没有什么难的,只有捋明白思路就简单
2:11