北大考研复试准备
Linux哲学思想
1、一切皆文件;
2、小型,单一用途的程序;
3、连接程序,共同完成复杂功能;
4、避免令人困惑的用户界面;
5、配置数据存储在文本中
linux 指令面试题 :https://zhuanlan.zhihu.com/p/74935718
面试题总结:https://blog.csdn.net/adminpd/article/details/122973684
静态变量、局部变量等
按存储区域分,全局变量、静态全局变量和静态局部变量都存放在内存的静态存储区域,局部变量存放在内存的栈区。
按作用域分,全局变量在整个工程文件内都有效;静态全局变量只在定义它的文件内有效;静态局部变量只在定义它的函数内有效,只是程序仅分配一次内存, 函数返回后,该变量不会消失;
局部变量在定义它的函数内有效,但是函数返回后失效。
集中式运算和分布式运算
所谓集中式计算就是指由一台或多台主计算机组成中心节点,数据集中存储在这个中心节点中,并且整个系统的所有业务单元都集中部署在这个中心节点上,系统的所有功能均能由其进行集中处理,其最大的特点就是部署结构简单。
而分布式计算主要研究如何应用分布式系统进行计算,即把一组计算机通过网络相互连接组成分散系统,然后将需要处理的数据分散成多个部分,交由分散在系统内的计算机组同时计算再将结果最终合并得到最终结果。
什么是数据挖掘?
**数据挖掘(Data Mining)**就是从大量的数据中,提取隐藏在其中的,事先不知道的、但潜在有用的信息的过程。
B/S架构、C/S架构、P2P架构
1、 C/S 架构是一种典型的两层架构,全称是Client/Server,即客户端/服务器端架构,其客户端包含一个或多个在用户的电脑上运行的程序,而服务器端有两种,一种是数据库服务器端,客户端通过数据库连接访问服务器端的数据;另一种是Socket服务器端,服务器端的程序通过Socket与客户端的程序通信。
比如:微信/客户端QQ等是基于C/S架构。
2、 B/S架构的全称为Browser/Server,即浏览器/服务器架构。Browser指的是Web浏览器,极少数事务逻辑在前端实现,但主要事务逻辑在服务器端实现,Browser客户端,WebApp服务器端和DB端构成所谓的三层架构。B/S架构的系统无须特别安装,只要有Web浏览器即可。
比如:IE浏览器/WEB端QQ等是基于B/S架构的。
3、P2P是英文Peer-to-Peer(对等)的简称,又被称为“点对点“。“对等”技术,是一种网络新技术,依赖网络中参与者的计算能力和带宽,而不是把依赖都聚集在较少的几台服务器上。
P2P还是英文Point to Point (点对点)的简称。它是下载术语,意思是在你自己下载的同时,自己的电脑还要继续做主机上传,这种下载方式,人越多速度越快但缺点是对硬盘损伤比较大(在写的同时还要读),还有对内存占用较多,影响整机速度。
P2P架构的核心思想是每个节点既可以充当客户端(Client),又可以充当服务器端(Server)。
比如:BT/电驴下载,非法传播视频的网站等,因为每个结点既是客户端可以进行下载,又是服务器端可以继续上传资源以提供下载服务给其他人,所以找不到真正的Server,打击非法网站也就难上加难了,所以P2P架构就是一种”我为人人,人人为我“的资源共享思想。如果是C/S架构,比如HTTP协议,只需单点攻击Server,整个C/S架构就失去了最核心的服务器端部分,基于C/S架构的通信也就被攻破了。
一些简称
IP Internet Protocol Address 互联网协议地址
MAC Media Access Control Address 媒体访问控制地址
DNS Domain Name System 域名系统
UDP User Datagram Protocol 用户数据报协议
TCP Transmission Control Protocol 传输控制协议
DHCP Dynamic Host Configuration Protocol 动态主机设置协议SSH
SSH Secure Shell 安全外壳协议
SSL Secure Sockets Layer 安全套接层
CDMA Code Division Multiple Access 码分多址
ARP Address Resolution Protocol 地址解析协议(ip->mac)
CSMA Carrier Sense Multiple Access 载波监听多路访问(CA,CD)
TLB translation look aside buffer 相联存储器
死锁
死锁产生的四个必要条件
1、互斥条件:资源是独占的且排他使用,进程互斥使用资源,即任意时刻一个资源只能给一个进程使用,其他进程若申请一个资源,而该资源被另一进程占有时,则申请者等待直到资源被占有者释放。
2、不可剥夺条件:进程所获得的资源在未使用完毕之前,不被其他进程强行剥夺,而只能由获得该资源的进程资源释放。
3、请求和保持条件:进程每次申请它所需要的一部分资源,在申请新的资源的同时,继续占用已分配到的资源。
4、循环等待条件:在发生死锁时必然存在一个进程等待队列{P1,P2,…,Pn},其中P1等待P2占有的资源,P2等待P3占有的资源,…,Pn等待P1占有的资源,形成一个进程等待环路,环路中每一个进程所占有的资源同时被另一个申请,也就是前一个进程占有后一个进程所深情地资源。
死锁预防:破坏234条件即可,1最好不破坏
死锁避免:银行家算法
死锁检测:资源分配图
进程线程区别
进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
线程:是进程的一个执行单元,是进程内调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
1、地址空间:线程共享本进程的地址空间,而进程之间是独立的地址空间。
2、资源:线程共享本进程的资源如内存、I/O、cpu等,不利于资源的管理和保护,而进程之间的资源是独立的,能很好的进行资源管理和保护。
3、健壮性:多进程要比多线程健壮,一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。
4、执行过程:每个独立的进程有一个程序运行的入口、顺序执行序列和程序入口,执行开销大。
但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,执行开销小。
5、可并发性:两者均可并发执行。
6、切换时:进程切换时,消耗的资源大,效率高。所以涉及到频繁的切换时,使用线程要好于进程。同样如果要求同时进行并且又要共享某些变量的并发操作,只能用线程不能用进程。
7、其他:线程是处理器调度的基本单位,但是进程不是。
堆和栈区别
堆与栈实际上是操作系统对进程占用的内存空间的两种管理方式,主要有如下几种区别:
(1)管理方式不同。栈由操作系统自动分配释放,无需我们手动控制;堆的申请和释放工作由程序员控制,容易产生内存泄漏(用完不回收);
(2)空间大小不同。每个进程拥有的栈大小要远远小于堆大小。理论上,进程可申请的堆大小为虚拟内存大小,进程栈的大小 64bits 的 Windows 默认 1MB,64bits 的 Linux 默认 10MB;
(3)生长方向不同。堆的生长方向向上,内存地址由低到高;栈的生长方向向下,内存地址由高到低。
(4)分配方式不同。堆都是动态分配的,没有静态分配的堆。栈有 2 种分配方式:静态分配和动态分配。静态分配是由操作系统完成的,比如局部变量的分配。动态分配由malloc()函数分配,但是栈的动态分配和堆是不同的,它的动态分配是由操作系统进行释放,无需我们手工实现。
堆和栈相比,由于大量malloc()/free()或new/delete的使用,容易造成大量的内存碎片,并且可能引发用户态和核心态的切换,效率较低。
栈相比于堆,在程序中应用较为广泛,最常见的是函数的调用过程由栈来实现,函数返回地址、EBP、实参和局部变量都采用栈的方式存放。虽然栈有众多的好处,但是由于和堆相比不是那么灵活,有时候分配大量的内存空间,主要还是用堆。
傅里叶变换的应用
傅立叶原理表明:任何连续测量的时序或信号,都可以表示为不同频率的正弦波信号的无限叠加。而根据该原理创立的傅立叶变换算法利用直接测量到的原始信号,以累加方式来计算该信号中不同正弦波信号的频率、振幅和相位。
可以将空域数据转化到频域,再使用滤波器可以去除一些噪音
O和 o
Ο,读音:big-oh;表示上界,小于等于。
Ω,读音:big omega、欧米伽;表示下界,大于等于。
Θ,读音:theta、西塔;既是上界也是下界,称为确界,等于。
ο,读音:small-oh;表示上界,小于。
ω,读音:small omega;表示下界,大于
当函数的大小只有上界,没有明确下界的时候,则可以使用大O表示法,该渐进描述符一般用于描述算法的 最坏复杂度。
当函数的大小只有下界,没有明确的上界的时候,可以使用大Ω表示法,该渐进描述符一般用与描述算法的 最优复杂度 。
P、NP、NPC问题
P问题:多项式时间内可解
NP问题:多项式时间内可构造并验证解
NPC问题:任何NP问题都可以在多项式时间被归约到此问题,并且可以在多项式时间内构造并验证此问题的解(同时属于NP与NP-hrad)
NP-hard问题:任何NP问题都可以在多项式时间被归约到此问题
NP问题,比如求图中两点最短路径,如果已知最短路径长度,那么就可以在多项式时间内验证这个解,验证过程所需要的时间复杂度为O(n)。如果要用算法来求解的话,我们可以这样来“猜测”它的解:先求一个总路程不超过 100的方案,假设我们可以依靠极好的运气“猜出”一个路线,使得总长度确实不超过100,那么我们只需要每次猜一条路一共猜n次。接下来我们再找总长度不超过 50 的方案,找不到就将阈值提高到75…… 假设最后找到了总长度为 90 的方案,而找不到总长度小于90的方案。们最终便在多项式时间O(n^k)内“猜”到了这个问题的解是一个长度为 90 的路线。
事务
指一个单元的工作,要么全做,要么全不做,保证一组数据的修改要么全部执行,要么全部不执行。
事务就是被绑定在一起作为一个逻辑工作单元的SQL语句分组,如果任何一个语句操作失败那么整个操作就被失败,以后操作就会回滚到操作前状态,或者是上有个节点。为了确保要么执行,要么不执行,就可以使用事务。
事务的特点——ACID: 原子性Atomicity(要么都做,要么都不做),一致性Consistency (运行中发生故障,必须回滚),隔离性Isolation (一个事务不能被其他事务干扰),持续性Durability(事务一旦提交,对数据库的改变应该是永久性的)。即“原隔一尺(持)”。
多态
在面向对象语言中,接口的多种不同实现方式就是多态。(允许将子类类型指针赋值给父类类型指针)
多态指同一个实体同时具有多种形式。
它是面向对象程序设计(OOP)的一个重要特征。多态,意味着一个对象有着多重特征,可以在特定的情况下,表现不同的状态,从而对应着不同的属性和方法。
多态前提——a.要有继承关系;b.要有方法重写;c.要有父类引用指向子类对象。
虚函数 C plus
允许被一个或多个派生类中重写的成员函数,以实现多态。
virtual 函数类型 函数名
封装
隐藏对象的属性和细节, 仅对外提供公共访问方式。(控制属性的读和修改的访问级别)
野指针
指向不可用内存区域的指针。
指针变量未初始化(会乱指,可能存储关键信息,一下子就被修改了),指针释放后未置空,指针操作超越变量作用域造成。对野指针进行操作很容易造成程序错误,甚至可能直接引起崩溃。
-野指针与空指针不同,野指针无法通过简单地判断是否为NULL避免。
-如何避免?
指针变量初始化置null,指针释放后置null.
const与define区别
(1) define定义的只是常数,不带类型;const定义的是常数不可改变,带类型。比如const int a = 10
(2) define在编译的预处理阶段起作用;const在编译、运行时起作用。
(3) define只是简单的字符串替换,没有类型检查,可能会导致边界效应。Const有对应的数据类型,要进行判断,避免低级错误。
const * p 指向常量的指针。
*const p 指针常量,指针指向的地址不变
const void *a这是定义了一个指针, 可以指向任意类型的值,但它指向的值必须是常量。
贪心、分治、动态规划
贪心算法:通过一系列的局部最优解来达到整体的最优解。可能找不到最优解
分治:将大问题分解为若干个子问题,在子问题下继续往下分,直达不能再分通过基本问题的结果,一步步向上,最终解决大问题。
动态规划dynamic programming:通过拆分,使问题能以分治的方式解决。将待解决问题分解为若干个子问题,按顺序求解,前一问题的解为后面问题的求解提供了有用信息。在求任意子问题时,通过决策,从局部解中选取保留最优的局部解。依次解决各子问题,最后一个子问题的解就是初始问题的解。
C语言中的static的作用
让一个变量长期有效,而不管在什么地方被申明, 相当于一个全局变量(被调用后值会保存)
Static作用域,全局。
比特币
比特币:P2P形式的数字货币,虚拟货币。依据特定算法,通过大量的计算产生
什么是死代码,注释掉的代码算死代码吗?
死代码主要是指1. 执行不到的代码. 2. 能够执行,但没有任何作用的代码。
死代码多半是因为前面执行过的某些转换而造成的。 总之: 死代码就是 “不产生实际作用”的代码。注释掉的代码应该不算死代码,有些代码被注释掉是为了修改或者调试方便,有可能系统功能修复完善后程序员又会把注释去掉。
死代码消除?
通过AQtime(性能优化工具)覆盖率的分析就可以发现所有的永远都不会执行到的代码,但是与程序无关的代码却不一定能够全部发现。
消除死代码(DCE)在某些情况下,编译器可以判断出某些代码根本不影响输出,所以编译器会消除这些代码。也可以使用优化作用进行消除。
死代码消除(Dead Code Elimination)是删除那些与特定源代码语句(其结果从未被使用过,或者条件块从不为True)关联的目标码。
函数指针干嘛用的?
1.函数指针作为函数的参数(将一个函数作为参数传递给另一个函数)
2.函数回调(我们用买东西做个比喻,普通调用就好比我们直接去买东西,到了商店就买到了东西;而函数回调就好比我们去蛋糕店预定一个蛋糕,这时蛋糕店肯定会留下你的联系方式,当蛋糕做好了,蛋糕店就会给你打电话,让你去取蛋糕。)
对大数据的了解?
“大数据”之“大”,并不仅仅指“容量大”,更大的意义在于通过对海量数据的交换、整合和分析,发现新的知识,创造新的价值,带来“大知识”、“大科技”、“大利润”和“大发展”。
大数据有着4“V”特征,即Volume(容量大)、Variety(种类多)、Velocity(速度快)和最重要的Value(价值密度低)。
Value的意思是指大数据的价值密度低。大数据时代数据的价值就像沙子淘金,数据量越大,里面真正有价值的东西就越少。现在的任务就是将这些ZB、PB级的数据,利用云计算、智能化开源实现平台等技术,提取出有价值的信息,将信息转化为知识,发现规律,最终用知识促成正确的决策和行动。
对云计算的理解?
云计算是一种模型,它可以随时随地、便捷地、随需应变地访问可配置计算资源共享池中的资源(如网络、服务器、存储、应用和服务),只需要最小的资源管理工作或与服务提供者进行交互,这些资源就能够被迅速供应和释放。
从广义上说,云计算是与信息技术、软件、互联网相关的一种服务,这种计算资源共享池叫做“云”,云计算把许多计算资源集合起来,通过软件实现自动化管理,只需要很少的人参与,就能让资源被快速提供。也就是说,计算能力作为一种商品,可以在互联网上流通,就像水、电、煤气一样,可以方便地取用,且价格较为低廉。
理解就是,租服务器,通过别人的资源帮忙计算。
4个实施模型:私有云、社区云、公有云和混合云
对云安全的理解?
“云安全(Cloud Security)”技术是网络时代信息安全的最新体现,它融合了并行处理、网格计算、未知病毒行为判断等新兴技术和概念,通过网状的大量客户端对网络中软件行为的异常监测,获取互联网中木马、恶意程序的最新信息,推送到Server端进行自动分析和处理,再把病毒和木马的解决方案分发到每一个客户端。
云安全技术是P2P技术、网格技术、云计算技术等分布式计算技术混合发展、自然演化的结果。
云 安全 通过网状的大量 客户端 对 网络 中软件行为的异常监测,获取 互联网 中 木马 、恶意程序的最新信息,推送到 服务端 进行自动分析和处理,再把病毒和木马的解决方案分发到每一个客户端。 整个 互联网 ,变成了一个超级大的 杀毒软件 ,这就是云 安全 计划的宏伟目标
汉诺塔
不难发现规律:1个圆盘的次数 2的1次方减1
2个圆盘的次数 2的2次方减1
3个圆盘的次数 2的3次方减1
。 。 。 。 。
n个圆盘的次数 2的n次方减1
汉诺塔思想,用递归。每次都分为第n个,和前n-1个。
(1)先把A柱上面的(N-1)个圆盘移到B柱(这一步使问题的规模减少了1)。
(2)再把A柱上剩下的那个最大的圆盘移到C柱。
(3)最后把B柱上的(N-1)圆盘移到C柱。
从这里入手,在加上上面数学问题解法的分析,我们不难发现,移到的步数必定为奇数步:
(1)中间的一步是把最大的一个盘子由A移到C上去;
(2)中间一步之上可以看成把A上n-1个盘子通过借助辅助塔(C塔)移到了B上,
(3)中间一步之下可以看成把B上n-1个盘子通过借助辅助塔(A塔)移到了C上;
public class Hanoilmpl {
public static void hanoi(int n, char A, char B, char C) {
if (n == 1) { // 终止条件
move(A, C);
} else {
hanoi(n - 1, A, C, B);//将n-1个盘子由A经过C移动到B
move(A, C); //执行最大盘子n移动
hanoi(n - 1, B, A, C);//剩下的n-1盘子,由B经过A移动到C
}
}
private static void move(char A, char C) {//执行最大盘子n的从A-C的移动
System.out.println("move:" + A + "--->" + C);
}
public static void main(String[] args) {
System.out.println("移动汉诺塔的步骤:");
hanoi(3, 'a', 'b', 'c');
}
}
约瑟夫环
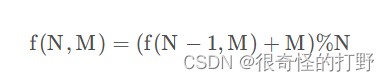

每杀掉一个人,下一个人成为头,相当于一个新的开始了,把数组向前移动M位。若已知N-1个人时,胜利者的下标位置位 f(N−1,M),则N个人的时候,就是往后移动M位,(因为有可能数组越界,超过的部分会被接到头上,所以还要模N),既
f ( N , M ) = ( f ( N − 1 , M ) + M ) % n
int cir(int n,int m)
{
int p=0;
for(int i=2;i<=n;i++)
{
p=(p+m)%i;
}
return p+1;
}
求平方根的算法
- 牛顿迭代法
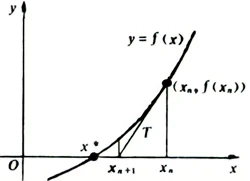

把求解一个数的平方根转化为求解问题, f(x) = x^2 - a,求解a的平方根变成了求f(x) = 0 的解
// 牛顿法
// f(x) = x^2 - a
// 求解 a 的平方根, 即求解 f(x) = 0 的解
// f(x) ~= f(x0) + (x - x0) * f'(x0);
// 令 f(x) = 0 => x = (x0 + a/x0) /2 => 得到该迭代公式.
class Solution {
public:
int mySqrt( int x ) {
long x0=x; //注意,这里必须是long类型,防止下面x0*x0溢出
while( x0*x0>x ) {
x0 = (x0 + x/x0)/2;
}
return (int)x0;
}
};
- 二分查找
链路与环
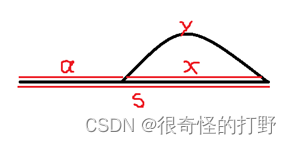
- 怎么判断有环
设置两个指针fast和slow,刚开始都指向链表头部,fast每次移动两个位置,slow每次移动一个位置,若两个指针相遇,说明有环。若fast为null, 则无环(null只能是地址,不能是int型,表示地址为空,即不存在)。
- 怎么找到环入口
从链表头、与第一次相遇点分别设一个指针,每次各走一步,两个指针再次相遇点就是环的入口。(当p1== p2时,p2所经过节点数为2x,p1所经过节点数为x,设环中有n个节点,p2比p1多走一圈有2x=n+x; n=x;可以看出p1实际走了一个环的步数,再让p2指向链表头部,p1位置不变,p1,p2每次走一步直到p1==p2; 此时p1指向环的入口。)
最长公共子序列

class Solution {
public int longestCommonSubsequence(String s1, String s2) {
int n = s1.length(), m = s2.length();
s1 = " " + s1; s2 = " " + s2;
char[] cs1 = s1.toCharArray(), cs2 = s2.toCharArray();
int[][] f = new int[n + 1][m + 1];
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
if (cs1[i] == cs2[j]) f[i][j] = f[i -1][j - 1] + 1;
else f[i][j] = Math.max(f[i - 1][j], f[i][j - 1]);
}
}
return f[n][m];
}
}
n个结点的平衡二叉树的深度为多少?
1 2 4 7 12 …
高度为h的AVL树最少节点
以此类推 1 2 4 7 12…
选出前n个最小的数
一千个数找1百个,直接快排
一千万/百万找出一百个最小的:最大堆
首先读入前100个数来创建大小为100的最大堆,建堆的时间复杂度为O(mlogm)(m为数组的大小即为100),然后遍历后续的数字,并于堆顶(最大)数字进行比较。如果比堆顶的数大,则继续读取后续数字;如果比堆顶数字小,则替换堆顶元素并重新调整堆为最大堆。直至全部遍历完为止。然后按照中序遍历的方式输出当前堆中的所有100个数字。该算法的时间复杂度为O(n)。
平衡二叉树的定义?
它或者是一棵空树,或者是具有下列性质的二叉树:它的左子树和右子树都是平衡二叉树,且左子树和右子树的高度差的绝对值不超过1。
指令是内核态的多还是用户态的多?
内核态。内核态的CPU可以访问内存所有数据,用户态下是受限访问,只能访问自己空间中的内存。
PCB
PCB(进程控制块process control block),一个数据结构,进程存在的唯一标志。系统通过PCB来了解进程的状态信息,以便控制和管理。
通常包含:PID,UID、进程当前状态、进程优先级、代码运行入口地址、程序的外存地址、代码段指针、数据段指针、状态字等。
进程实体由:代码段、数据段、PCB组成。
为了深刻描述程序动态执行过程的性质乃至更好的支持和管理多道程序的并发执行,人们引入了进程的概念。
FAT
FAT(文件配置表file allocation table),分配给文件的所有盘块号都放在该表中,记录了文件所在位置。
提高并行
多道程序设计
中断
解决处理器速度和硬件速度不匹配,是多道程序设计的必要条件。
每个中断都有自己的数字标识,当中断发生时,指令计数器PC和处理机状态字PSW中的内容自动压入处理器堆栈,同时新的PC和PSW的中断向量也装入各自的寄存器中。这时,PC中包含的是该中断的中断处理程序的入口地址,它控制程序转向相应的处理,当中断处理程序执行完毕,该程序的最后一条iret(中断返回),它控制着恢复调用程序的环境。-
-中断后保存什么?
保存pc, psw, 通用寄存器。Pc程序计数器program count,存放下一条指令所在的单元的地址。
psw,program status word程序状态字,指处理器的状态。
对中断的理解?
计算机执行过程中,出现异常情况或者特殊请求时,计算机停止现行程序的运行,转向对这些异常情况或特殊请求的处理,处理结束后再回到中断点处,继续执行原程序。
操作系统设计哪些方面?
进程(处理机)管理,存储器(内存)管理,设备管理,文件管理,操作系统与用户之间的接口。
中断和系统调用的区别
中断是由外设产生, 无意的, 被动的
系统调用是由应用程序请求操作系统提供服务产生,是有意的、主动的。要从用户态通过中断进入内核态。(联系)
从如下几个方面对三者进行比较:
1)源头
中断:外设引起
系统调用:应用程序请求操作系统提供服务
2)响应方式
中断:异步
系统调用:异步或同步
3)处理机制
中断:持续,对用户应用程序是透明的
系统调用:等待和持续
存储区:
静态存储区:永恒存在不消失,与程序永存,包括常量、全局变量、常变量(const变量)、静态变量。
动态存储区:会变化的,存放堆和栈。栈存放函数的返回地址、参数和局部变量。堆存放new运算符和malloc函数分配得到的空间。
共享存储区:进程通信的一种方式。通信的两个进程之间存在一块共享空间,通过对其读写操作来进行信息交换。
进程通信:
-高级通信方式:消息传递,共享存储,管道通信
-低级通信方:PV
内存泄露
指程序中己动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
静态变量与程序生命周期一致,因此对象常驻内存,造成内存泄漏
内存溢出
内存溢出是指存储的数据超出了指定空间的大小,这时数据就会越界,举例来说,常见的溢出,是指在栈空间里,分配了超过数组长度的数据,导致多出来的数据覆盖了栈空间其他位置的数据,这种情况发生时,可能会导致程序出现各种难排查的异常行为,或是被有心人利用,修改特定位置的变量数据达到溢出攻击的目的。
页面置换
页面置换:FLOC, 先进先出,最佳置换,最近最久未使用LRU,时钟置换
内存分配
内存分配:单一连续分配,固定分区分配,动态/可变分区分配(首次适应,最佳适应,最坏适应,邻近适应(同首次,只不过从上次查找结束位置开始查找)),一(分配),就有好有坏
TLB
TLB; translation look aside buffer高速缓冲存储器, 又称联想存储器, 也称快表技术.存放进程正在访问的页表项,为了加快地址映射速度.
有并行查找能力: 多 CPU 让查询更快的查询
若页表全在内存中,读取一个数据至少要访问内存,一起找到物理地址,一次取数据。为了提高速度,引入快表。
虚拟内存在哪?
虚拟内存在外存上。基于局部性原理,应用程序在运行之前并不必全部装入内存,仅需将当前运行到的那部分程序和数据装入内存便可启动程序的运行,其余部分仍驻留在外存上。当要运行的指令或访问的数据不在内存时,再由操作系统通过请求调入功能将它们调入内存,以使程序能继续运行。如果此时内存已满,则还需通过置换功能,将内存中暂时不用的程序或数据调至盘上,腾出足够的内存空间后,再将要访问的程序或数据调入内存,使程序继续运行。
实现虚拟内存的硬件基础:一定容量的内存; 大容量的外存; 地址变换机构(含快表); 缺页中断机构。
Tcp和Udp的区别?
TCP:面向连接,提供可靠交付,面向字节流,全双工。每一条tcp连接只能有两个端点。
UDP:无连接,尽最大努力交付,面向报文, 首部开销小,不提供流量控制, 没有拥塞控制 (两个都是连接的事),不保证顺序接受。支持一对一,一对多,多对一,多对多的交互通信。
1)tcp基于连接,udp无连接;
2)TCP要求系统资源较多,UDP较少;
3)UDP程序结构较简单 ;
4)流模式(TCP)与数据报模式(UDP);
5)TCP保证数据正确性,UDP可能丢包 ;
6)TCP保证数据顺序,UDP不保证 。
静态路由、动态路由
静态路由:由用户或网络管理员手工配置的路由信息。当网络的拓补结构或链路的状态发生变化时,网络管理员需要手工去修改路由表中相关的静态路由信息。
动态路由:路由器中的路由表项由相连的路由器之间交换信息,会不断更新
RIP(UDP):距离向量算法,路由器根据距离选择路由,允许最大站点数为15,RIP每隔30秒做一次路由信息广播。
OSPF(直接装在IP报文里):链路状态路由算法,洪泛法,每个路由器向邻接路由器发送链路状态广播信息。迪杰斯特拉算法。
BGP(TCP):外部网关协议
RIP、BGP应用层,OSPF网络层。
DNS递归三个步骤:
1、如果主机所询问的本地域名服务器不知道被查询域名的ip地址,
2、那么本地域名服务器就以DNS客户的身份,向根域名服务器继续发出查询请求报文(即替该主机查询),而不是让该主机自己进行下一步查询。
网络拓扑结构:
星形: 每个终端都以单独的线路与中央设备相连。特点便于集中控制和管理,成本高,中心结点对故障敏感。
总线形:单根传输线把计算机连接起来。建网容易,重负载通信效率不高,总线任一处对故障障碍。
环形:所有计算机接口设备连接成一个环。环中信号是单向传输。
网状形:每个结点至少有两条路径和其他结点相连。可靠性高,控制复杂,线路成本高
各层协议
物理层:ADSL SONET/SDH
数据链路层:PPP PPPoE HDLC L2TP
网络层:ARP ICMP IGMP IP IPsec OSPF
传输层:TCP UDP SSL/TLS(这个是传输层和应用层的中间层协议,可以归到传输层来)
应用层:DHCP RIP BGP HTTP FTP SMTP POP3
流量控制、拥塞控制
流量控制:控制发送方的发送速度,是接收方有足够的缓冲空间来接受。停止-等待,滑动窗口。
拥塞控制:通过控制发送方的发送速度,放置过多的数据进入网络,造成通信时延的增加,是全局性。慢开始,快重传,快恢复。
奇、偶校验的区别?
奇校验和偶校验就是附加上一个0或者1让待检测数据中的1为奇数或者偶数。
例如:偶校验:a、如果传输的数据1的个数为偶数,则校验位为0
b、如果传输的数据1的个数为奇数,则校验位为1(凑成偶数个1)
数据链路层的形成帧(组帧)的方式有哪些?
字符计数法
字符填充的首尾定界符法
比特填充的首尾标志法
违规编码法
如何查询订单,用什么数据结构,索引
建立索引,create unique index 索引名 on 表名
Select * from 订单 where 订单号=‘XXXXX’,* 表示所有信息。
存储过程(数据库)
定义:一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译。
如何调用存储过程?
通过指定存储过程的名字并给出参数来执行
使用索引查询一定能提高查询性能吗?
不一定。通常索饮查询比全表查询要快,但是索引需要空间来存储,定期要维护,而且当表中记录增减或更改时,索引本身也会更改,也会带来额外的I/O操作。
矩阵的秩
矩阵的最高阶非零子式,其阶数就是秩。
求特征向量和特征值
A为n阶矩阵,数入和n维非零列向量x,当Ax=入x时,入为A特征值,x为特征向量。
令(入E-A)的行列式为0,求得特征值。
核函数

KKT条件
Karush-Kuhn-Tucker (KKT)条件是非线性规划(nonlinear programming)最佳解的必要条件。KKT条件将Lagrange乘数法(Lagrange multipliers)所处理涉及等式的约束优化问题推广至不等式。
在解决不等式优化问题时,使用到KKT条件。



逻辑回归和SVM比较
相同点:
-
Logistic回归和SVM都是分类算法.
-
如果不考虑使用核函数,LR和SVM都是线性分类模型,也就是说它们的分类决策面是线性的。
-
都是有监督学习的算法
-
LR和SVM都是判别模型。
不同点:
-
损失函数不同
LR基于概率理论,通过极大似然估计方法估计出参数的值,然后计算分类概率,取概率较大的作为分类结果。SVM基于几何间隔最大化,把最大几何间隔面作为最优分类面。 -
SVM只考虑分类面附近的局部的点,即支持向量,LR则考虑所有的点,与分类面距离较远的点对结果也起作用,虽然作用较小。
-
在解决非线性分类问题时,SVM采用核函数,而LR通常不采用核函数。
-
SVM不具有伸缩不变性,LR则具有伸缩不变性。
-
Logistic回归是通过sigmoid函数来进行分类的,类别分为{0,1}.
SVM是通过sign函数来进行分类的,类别分为{+1,-1}.
召回率、精确率、准确率、F1指标的作用以及区别?
召回率(Recall)–>预测正确的真正例/全部真正例
精确率(Precision)–>预测正确的真正例/被预测为真正例的所有样本数
准确率(Accuracy)–>预测正确的正负样本数/样本总数
F1值–> 2/(1/Precision +1/Recall)–>精确率和召回率的调和平均值
集成学习的原理/作用是什么?
原理:’博采众长’
作用:根据一定的结合策略,将多个弱学习器组成一个强学习器.
在机器学习中,模型的选择指的是?如何进行模型选择?
模型选择就是算法模型及模型参数的选择.(就是说选择什么算法)
如何进行模型选择—>交叉验证,选择效果好的模型.
损失函数、代价函数、目标函数的区别?
损失函数(代价函数)–>损失函数越小,就代表模型拟合的越好。
目标函数–>把要最大化或者最小化的函数(模型迭代时的迭代方向,往目标函数最小化的方向迭代)称为目标函数.有正则项的必定是目标函数.
损失函数一般针对单个样本
代价函数一般针对总体
目标函数一般有正则项
常见的距离度量公式有那些?
1)Minkowski(闵可夫斯基距离)
--- P=1:曼哈顿距离(城市距离)
---P=2:欧式距离
---P无穷:切比雪夫距离
2) 夹角余弦相似度
3) KL距离(相对熵)
4) 杰卡德相似度系数(集合)
5) Pearson相关系数ρ(距离= 1-ρ)
什么是交叉验证?交叉验证的作用是什么?
交叉验证就是将原始数据集(dataset)划分为两个部分.一部分为训练集用来训练模型,另外一部分作为测试集测试模型效果.
作用:
1)交叉验证是用来评估模型在新的数据集上的预测效果,也可以一定程度上减小模型的过拟合
2)还可以从有限的数据中获取尽可能多的有效信息。
交叉验证主要有以下几种方法:
①留出法.简单地将原始数据集划分为训练集,验证集,测试集三个部分.
②k折交叉验证.(一般取5折交叉验证或者10折交叉验证)
③留一法.(只留一个样本作为数据的测试集,其余作为训练集)—只适用于较少的数据集
④ Bootstrap方法.(会引入样本偏差)
什么是机器学习的欠拟合?
所谓欠拟合就是模型复杂度低或者数据集太小,对模型数据的拟合程度不高,因此模型在训练集上的效果就不好.
如何避免欠拟合问题?
1.增加样本的数量
2.增加样本特征的个数
3.可以进行特征维度扩展
什么是偏差(bias)、方差(variable)之间的均衡?
Bias 是由于你使用的学习算法过度简单地拟合结果或者错误地拟合结果导致的错误。它反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,即算法本身的拟合能力。
Bias 可能会导致模型欠拟合,使其难以具有较高的预测准确性,也很难将你的知识从训练集推广到测试集。
Variance 是由于你使用的学习算法过于复杂而产生的错误。它反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性,反应预测的波动情况。
Variance 过高会导致算法对训练数据的高纬度变化过于敏感,这样会导致模型过度拟合数据。从而你的模型会从训练集里带来太多噪音,这会对测试数据有一定的好处。
为什么我们要称“朴素”贝叶斯?
尽管 Naive Bayes 具有实际应用,特别是在文本挖掘中,但它被认为是“天真的”,因为它假设在实际数据中几乎不可能看到:条件概率被计算为组件个体概率的纯乘积。 这意味着特征的绝对独立性 – 这种情况在现实生活中可能永远不会遇到。
正如 Quora 上一些评论者所说的那样,Naive Bayes 分类器发现你喜欢泡菜和冰淇淋之后,可能会天真地推荐你一个泡菜冰淇淋。
生成模型和判别模型




什么是F1数,怎么使用它?
F1分数是衡量模型性能的指标。它是模型精度和召回的加权平均值,结果趋向于1是最好的,结果趋向于0是最差的。你可以在分类测试中使用它,而真正的否定并不重要。
比较Boosting和Bagging的异同
二者都是集成学习算法,都是将多个弱学习器组合成强学习器的方法。
Bagging:从原始数据集中每一轮有放回地抽取训练集,训练得到k个弱学习器,将这k个弱学习器以投票的方式得到最终的分类结果。
Boosting:每一轮根据上一轮的分类结果动态调整每个样本在分类器中的权重,训练得到k个弱分类器,他们都有各自的权重,通过加权组合的方式得到最终的分类结果。
什么是k折交叉验证?
将原始数据集划分为k个子集,将其中一个子集作为验证集,其余k-1个子集作为训练集,如此训练和验证一轮称为一次交叉验证。交叉验证重复k次,每个子集都做一次验证集,得到k个模型,加权平均k个模型的结果作为评估整体模型的依据。
用来进行模型选择
Dropout为什么可以减少过拟合
A 记忆随机抹去,不再死记硬背
B 减少联合依赖性,每个神经元都得独当一面
C 有性繁殖
D 数据增强
梯度爆炸的解决方法?
针对梯度爆炸问题,解决方案是引入Gradient Clipping(梯度裁剪)。通过Gradient Clipping,将梯度约束在一个范围内,这样不会使得梯度过大。
简述EM算法的原理
EM算法用于求解带有隐变量的最大似然估计问题。由于有隐变量的存在,无法直接用最大似然估计求得对数似然函数极大值的公式解。此时通过jensen不等式构造对数似然函数的下界函数,然后优化下界函数,再用估计出的参数值构造新的下界函数,反复迭代直至收敛到局部极小值点
求二叉树的直径?
两次 DFS,第一次找出距离 root 最远点,第二次以第一次结果为起点找出第二个点,这两点的距离即为直径。
系统调用的定义?
系统调用是 OS 与应用程序之间的接口,它是用户程序取得 OS 服务的唯一途径。 它与一般的过程调用的区别:运行在不同的系统状态, 调用程序运行在用户态,而被调用的程序运行在系统态,通过软中断机制,先由用户态转为系统态,经核心分析后,才转向相应的系统调用处理子程序;一般的过程调用返回后继续执行, 但对系统调用,当调用进程仍具有最高优先权时,才返回到调用进程继续处理,否则只能等被重新调度。
进程的三个组成部分?
程序段、数据段、 PCB(Process Control Block)
进程切换的过程?
保持处理机上下文 -> 更新 PCB -> 把 PCB 移入相应队列(就绪、阻塞) ->选择另一个进程并更新其 PCB -> 更新内存管理的数据结构 -> 恢复处理机上下文
FCB 包含什么?
文件指针:上次读写位置。
文件打开数:多少个进程打开了此文件。
文件磁盘位置。
文件的访问权限:创建、只读、读写等。
页面置换算法?
A:
最佳置换算法 OPT
先进先出置换算法 FIFO
最近最久未使用算法 LRU
时钟算法 LOCK
改进型时钟算法
处理作业调度算法?
A:
先来先服务 FCFS
最短作业优先 SJF
最高响应比优先 HRN
多级队列调度算法
进程调度算法?
A:
先进先出 FIFO
时间片轮转算法 RR
最高优先级算法 HPF
多级队列反馈算法
磁盘调度算法?
A:
先来先服务 FCFS
最短寻道时间优先 SSTF
扫描算法 SCAN
循环扫描算法 C-SCAN
三级模式、二级映像
键、超键、候选键、主键、外键
键:关系某些属性的集合具有区分不同元组的作用,称为键(key)
超键:某一组属性的值能唯一的标识每个元组,则成该属性为 超键
候选键:极小的超键
主键:人为指定的一个候选键,主键值必须唯一非空
外键:不同关系中的元组可以存在联系,这种联系是通过外键建立起来的,一个关系的外键必须参照另一个关系的主键
函数依赖
主属性:在一个关系中,如一个属性是构成某一个候选关键字的属性集中的一个属性
完全函数依赖:一个属性或属性集合可以完全决定另一个属性,缺少任何一个属性都不行。
比如 (学号,课程名)——>分数
部分函数依赖:指的是属性集合的一个子集就可以完全决定另一个属性
比如 (学号,课程名) ——> 姓名
传递函数依赖:
比如: 学号——>院系——>院主任
范式
解决方法都是拆分关系
第一范式 1NF
定义: 属于第一范式关系的所有属性都不可再分,即数据项不可分。
理解: 第一范式强调数据表的原子性,是其他范式的基础。如下图所示数据库就不符合第一范式:

上表将商品这一数据项又划分为名称和数量两个数据项,故不符合第一范式关系。改正之后如下图所示:
**
缺点:冗余信息多,插入删除会出现问题,修改繁琐
第二范式2NF**
定义: 满足 1NF 前提下,存在一个候选码,非主属性全部依赖该候选码,即存在主键,体现唯一性,专业术语则是消除部分函数依赖(需要完全函数依赖)
缺点:冗余信息多,插入删除会出现问题,修改繁琐
第三范式3NF
满足 2NF 前提下,非主属性必须互不依赖,消除传递依赖
BC范式
满足3NF前提下,消除主属性对候选键的部分函数依赖
索引
索引是对数据库表中一列或多列的值进行排序的数据结构,用于快速访问数据库表中的特定信息。
从物理结构上可以分为聚集索引和非聚集索引两类:
聚簇索引:指索引的键值的逻辑顺序与表中相应行的物理顺序一致,即每张表只能有一个聚簇索引,也就是我们常说的主键索引;
非聚簇索引的逻辑顺序则与数据行的物理顺序不一致。
索引优缺点
先来说说优点:
-
创建索引可以大大提高系统的性能。
-
通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
-
可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
-
可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
-
在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。
-
通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
既然增加索引有如此多的优点,为什么不对表中的每一个列都创建一个索引呢?这是因为索引也是有缺点的:
-
创建和维护索引需要耗费时间,这种时间随着数据量的增加而增加,这样就降低了数据的维护速度。
-
索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间。如果要建立聚簇索引,那么需要的空间就会更大。
小表不建议索引,全表扫描可能都比索引块,因为在mysql上的索引都是聚簇索引,当要查询的值不在主键上,就需要回表操作(拿着从辅助索引中查到的主键值去聚簇索引中查询数据),更慢。
索引是用来查找的,如果插入大量数据最好先删除索引,再插入。
索引的数据结构?
索引的数据结构和具体存储引擎的实现有关,MySQL 中常用的是 Hash 和 B+ 树索引。
Hash 索引底层就是 Hash 表,进行查询时调用 Hash 函数获取到相应的键值(对应地址),然后回表查询获得实际数据.
B+ 树索引底层实现原理是多路平衡查找树,对于每一次的查询都是从根节点出发,查询到叶子节点方可以获得所查键值,最后查询判断是否需要回表查询.
为什么 B+ 树比 B 树更适合应用于数据库索引?
B+ 树减少了 IO 次数。
由于索引文件很大因此索引文件存储在磁盘上,B+ 树的非叶子结点只存关键字不存数据,因而单个页可以存储更多的关键字,即一次性读入内存的需要查找的关键字也就越多,磁盘的随机 I/O 读取次数相对就减少了。
B+ 树查询效率更稳定
由于数据只存在在叶子结点上,所以查找效率固定为 O(log n),所以 B+ 树的查询效率相比B树更加稳定。
B+ 树更加适合范围查找
B+ 树叶子结点之间用链表有序连接,所以扫描全部数据只需扫描一遍叶子结点,利于扫库和范围查询;B 树由于非叶子结点也存数据,所以只能通过中序遍历按序来扫。也就是说,对于范围查询和有序遍历而言,B+ 树的效率更高。
什么是脏读、幻读和不可重复度?
脏读:一个事务读取到另一个事务尚未提交的数据。 事务 A 读取事务 B 更新的数据,然后 B 回滚操作,那么 A 读取到的数据是脏数据。
不可重复读:一个事务中两次读取的数据的内容不一致。 事务 A 多次读取同一数据,事务 B 在事务 A 多次读取的过程中,对数据作了更新并提交,导致事务 A 多次读取同一数据时,结果 不一致。
幻读:一个事务中两次读取的数据量不一致。 系统管理员 A 将数据库中所有学生的成绩从具体分数改为 ABCDE 等级,但是系统管理员 B 就在这个时候插入了一条具体分数的记录,当系统管理员 A 改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。 解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。
表和视图的关系
视图其实就是一条查询sql语句,用于显示一个或多个表或其他视图中的相关数据。 表就是关系数据库中实际存储数据用的。
视图:是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增,改,查,操作,试图通常是有一个表或者多个表的行或列的子集。对视图的修改不会影响基本表,保证安全性。它使得我们获取数据更容易,相比多表查询。
视图的优缺点
优点: 1)对数据库的访问,因为视图可以有选择性的选取数据库里的一部分。 2 )用户通过简单的查询可以从复杂查询中得到结果。 3 )维护数据的独立性,试图可从多个表检索数据。 4 )对于相同的数据可产生不同的视图。 缺点: 性能:查询视图时,必须把视图的查询转化成对基本表的查询,如果这个视图是由一个复杂的多表查询所定义,那么,那么就无法更改数据
锁
锁:在所以的DBMS中,锁是实现事务的关键,锁可以保证事务的完整性和并发性。与现实生活中锁一样,它可以使某些数据的拥有者,在某段时间内不能使用某些数据或数据结构。当然锁还分级别的。
共享锁(S锁):事务T只有获得了对象A的共享锁才能读A
互斥锁(X锁):事务T获得对象A的X锁即可读写A
计算机网络为什要分层?
- 各层之间独立。
- 灵活性好。
- 易于实现和维护。
- 促进标准化工作,因为每一层的功能都事先定义好了
当然,分层当然也有一些缺点,比如有些功能会在不同的层次中重复出现,因而产生了额外开销。
寻找数组中第K大的数的方法
利用快速排序的思想,从数组S中随机找出一个元素X,把数组分为两部分Sa和Sb。Sa中的元素大于等于X,Sb中元素小于X。这时有两种情况:
1. Sa中元素的个数小于k,则Sb中的第k-|Sa|个元素即为第k大数;
2. Sa中元素的个数大于等于k,则返回Sa中的第k大数。时间复杂度近似为O(n)
两个队列模仿一个栈?
入栈:入 A 队
出栈:将 A 队除队尾元素全部转移到 B 队,出 A 队, 算法思想就是两个队列倒来倒去,只留一个元素时出栈。
循环比递归效率高吗
循环和递归式可以互换的,不能决定性地这样说
递归的优点是:代码简洁清晰,容易检查正确性;缺点是:当递归调用的次数较多的时候,要增加额外的堆栈处理,可能产生堆栈溢出,对执行效率有一定影响。
循环的优点是:结构简单,速度快;缺点是并不能解决所有问题,有的问题适合于递归解决
图论知识点
图:一个图是一个有序对<V, E>,记为G=(V, E),其中:
- V是一个有限的非空集合,称为顶点集合,其元素称为顶点或点。用|V|表示顶点数;
- E是由V中的点组成的无序对构成的集合,称为边集,其元素称为边,且同一点对在E中可以重复出现多次。用|E|表示边数
图的阶数:也就是图的顶点数
简单图 :没有环(自己到自己的边)也没有重边的图,除此之外都是复合图
多重图:含有平行边的图称为多重图。 也称若图中某两个结点之间的边数多于一条,又允许顶点通过同一条边和自己关联,则称为多重图。
点集与边集均为有限集合的图称为有限图。只有一个顶点而无边的图称为平凡图。边集为空的图称为空图
偶图(二部图):点集可以划分为两个非空子集X、Y,使得每一条边,一个顶点在X、另一个在Y。
正则图:所有顶点的度都相同的图
补图:该图对应的完全图,减去该图所有的边,剩下的边和所有顶点构成的图就是该图的补图
同构:不区分顶点的话,两个图结构相同就称为同构
树的定义:连通的无圈图
森林:无圈图G为森林
途径(闭途径):给定图G = (V, E),w =v0 e1 v1 e2 … ek vk 是G中点边交替组成的序列,其中vi∈V,ei∈E,若w满足ei的端点为vi-1与vi,则称w为一条从顶点v0到顶点vk的途径(或通道或通路),简称(v0, vk)途径。顶点v0和vk分别称为w的起点和终点,其他点称为内部点,途径中的边数称为它的长度。起点和终点相同的途径就称为闭途径(环游)
迹(闭迹):边不重复的途径称为迹,起点终点相同的迹为闭迹(回路)
路(圈):点不重复的迹称为路,起点终点相同的路成为圈
连通分支:在非连通图G中,每一个极大的连通部分为G的连通分支,G的连通分支的个数,称为G 的分支数,记为ω(G)。
欧拉路径:图 上有一条经过所有顶点、所有边的简单路径(边不重复、点可以重复)
欧拉回路:图 上有一条经过所有顶点、所有边的简单回路(边不重复,点可以重复)
欧拉图:一笔把所有边走完,点可以重复
欧拉有向图:有欧拉回路的连通有向图
无向欧拉图判别法:G是无向欧拉图 ,G是连通图且G无奇度顶点
下图中,(a)是欧拉图,也是欧拉回路,©是欧拉路径,(b)两者都不是,但是是哈密顿图
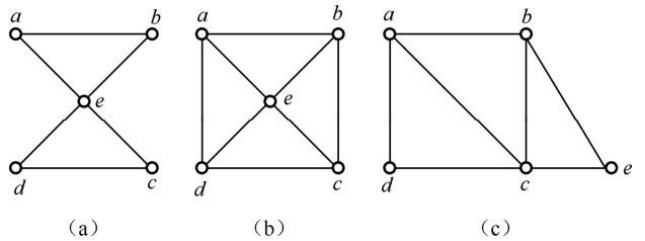
哈密顿回路:所有顶点经过一次的简单回路
哈密顿图:一笔将所有点走完,并回到原点,有些边可以不走
1.美国图论数学家奥勒在1960年给出了一个图是哈密尔顿图的充分条件:对于顶点个数大于2的图,如果图中任意两点度的和大于或等于顶点总数,那这个图一定是哈密顿图。但不满足不一定就不是哈密顿图
2.若图的最小度不小于顶点数的一半,则图是哈密顿图;
3.若图中每一对不相邻的顶点的度数之和不小于顶点数,则图是哈密顿图。不满足不一定就不是
例2:下图中,图(a)和(b)中有哈密顿回路,为哈密顿图,图©中有哈密顿路径,(d)中两者均无
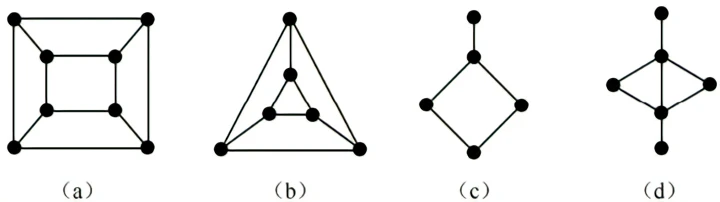
PS:欧拉图与哈密顿图对比,欧拉图遍历的是边,而哈密顿图遍历的是结点。
平凡图是哈密顿图
集合论知识点
什么是集合?:由离散个体构成的整体的称为集合,称这些个体为集合的元素。
什么是幂集?: 集合的全体子集构成的集合叫做幂集。
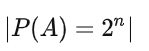
什么是笛卡尔乘积?
设有两个集合 A 与 B,用 A 与 B 中的元素组成有序偶,以 A 的元素作为有序偶的第一个分量,以 B 的元素作为有序偶的第二个分量,用这种方式所组成的有序偶的全体构成一个集合,称为 A 与 B 的笛卡尔乘积
怎么判断两个无穷集合的大小?
对无限集,通过建立一一对应的方法可以比较它们元素个数的大小(在集合论中称为势),以整数集 Z 和偶数集 A 为例,如果将 Z 中的每一个元素都乘以 2,则都可以在 A 中找到对应的偶数元素,即 Z 和 A 中的元素是一一对应的,也就是说这两个集合是等势的。值得注意的是,偶数集合是整数集合的一部分,但它包含的元素个数却跟整数集合一样多。
n阶行列式定义
n阶行列式是由n个n维向量组成,其运算结果是以这n个向量为邻边的n维图形的(有向)体积
矩阵的秩
设A是mxn 矩阵,A中最大的不为0的子式的阶数称为A的秩,
python中indent什么意思
在Python中,缩进(indent)是指在代码块内使用空格或制表符,以使代码在视觉上更易于理解。Python中缩进的使用是强制性的,因为它用于确定代码块的开始和结束。
IEEE和ACM的中英文全称
IEEE的中文全称为“电气和电子工程师协会”(Institute of Electrical and Electronics Engineers)
ACM的中文全称为“计算机协会”(Association for Computing Machinery)。
怎么从100w个数中找到第20w小的数。
建立一个最大容量为 20w 的小根堆即可,初始化为MAX值,遍历一遍数据,20w小的数据被放在堆中,然后逐个排出,留下的就是target。
什么叫做http无状态,以及为什么要无状态,怎么让它有状态。
HTTP是一种无状态的协议,这意味着服务器在处理客户端请求时不会保留任何先前的状态或上下文信息。每个HTTP请求都是独立的,服务器无法识别相同客户端发出的不同请求之间的联系。
HTTP协议被设计成无状态的原因是为了提高可伸缩性和可靠性。如果服务器需要在处理每个请求时都保留先前的状态信息,那么它将需要更多的资源来处理并维护这些状态,这可能会导致服务器性能下降或崩溃。
虽然HTTP是无状态的协议,可以使用Cookie来跟踪用户会话状态,或者使用服务器端会话来存储和检索状态信息。在使用这些技术时,服务器将为每个客户端维护一些状态信息,以便在后续的请求中使用。
详细讲一下TCP阻塞控制?
A:慢启动:慢启动是TCP阻塞控制中的一种算法,用于在连接开始时逐渐增加发送方发送数据的速度,避免网络拥塞。在慢启动阶段,从1开始,发送窗口大小按指数增长,逐渐到threshold。
拥塞避免:用于在慢启动后逐渐增加发送数据的速度,同时避免网络拥塞。拥塞避免算法使用了一个叫做拥塞窗口的变量,发送窗口>threshold之后会线性增长,直到发生超时\冗余ac k。
快速重传:当发送方接收到三个相同的确认应答时,就会认为有数据包丢失,并立即重传数据包,以避免等待超时的情况发生。这个过程被称为快速重传。
快速恢复:在快速重传之后,降低threshold为当前发送窗口的一半,并且将当前发送窗口设置为threshold,直接进入线性增长。
超时重传:如果发送方没有收到确认应答,就会认为数据包丢失,并重新发送数据包。
如何求圆周率?
随机投点法(蒙特卡罗方法):在一个正方形内,向其中随机投掷大量的点,根据圆的面积与正方形面积的比值,可以计算出圆周率的近似值。
说说冯诺依曼体系结构吧
冯·诺伊曼体系结构,也称为存储程序计算机,是计算机硬件结构的一种基本模型。它最早由美国数学家约翰·冯·诺伊曼提出,主要包括以下几个方面:
存储器:计算机的存储器被分为两个部分,分别是程序存储器和数据存储器。程序存储器用于存储计算机程序,数据存储器则用于存储程序运行时所需要的数据。
运算器:计算机的运算器是用于执行算术和逻辑运算的部件,通常包括加法器、减法器、乘法器、除法器、位移器等。是核心部件。
控制器:计算机的控制器用于控制程序的执行流程,它从程序存储器中取出指令并解析执行,根据指令的不同进行不同的操作。
还有输入/输出设备等。
冯·诺伊曼体系结构的最大特点是采用了存储程序的思想,即将计算机程序也视为一种数据,与数据存储在同样的存储器中。这种思想使得程序能够像数据一样被处理,大大提高了计算机的灵活性和通用性。
算法复杂度与初始顺序无关
A:选择、堆、归并、基数
总比较次数与初始状态无关:
A:选择、基数
总移动次数与初始状态无关:
A:归并、基数
C语言中二进制文件和文本文件的区别是什么?
A:在C语言中,二进制文件和文本文件是两种不同的文件类型,它们的主要区别如下:
存储方式:文本文件是以ASCII码方式存储数据,而二进制文件是以二进制格式存储数据。
数据类型:文本文件只能存储字符和字符串等文本类型数据,而二进制文件可以存储任意类型的数据,包括整型、浮点型、结构体等。
可读性:文本文件是可读的,而二进制文件是不可读的。
文件大小:相同数据量的文本文件通常比二进制文件要大,因为文本文件需要保存每个字符的ASCII码值和一些控制字符,而二进制文件则可以使用更紧凑的格式来存储数据。
总的来说,文本文件适合存储文本类型数据,例如配置文件、日志文件等,而二进制文件适合存储任意类型的数据,例如图像、音频、视频等。
中心极限定理是什么
A:中心极限定理(Central Limit Theorem,CLT)是概率论中的一条重要定理,指的是在一定条件下,许多独立随机变量的和或平均值的分布趋近于正态分布。
中心极限定理在统计学中有着广泛的应用,例如:
在一定条件下,样本均值的分布会趋近于正态分布,这为使用正态分布的统计推断方法提供了理论基础。
在大量样本的情况下,可以使用正态分布来估计总体均值和标准差,从而为参数估计提供了依据。
大数定律是什么?
A:大数定律(Law of Large Numbers)是概率论中的一条定理,描述了随着样本数量的增加,样本均值趋向于总体均值的现象。简单来说,就是当重复进行同一实验时,随着实验次数的增加,实验结果的平均值会趋向于理论期望值。该定律提供了一种可靠的方法来对随机事件的结果进行预测和估计。在统计学、经济学、物理学、工程学等领域广泛应用。
置信度和置信区间是什么,一般是怎么选取的。
置信度和置信区间是统计学中的概念,用于表示对总体参数的估计值的不确定性程度。
置信度是指在相同的条件下,通过不断抽取样本并计算估计值,其中有多少比例的估计值会落在一定的置信区间内。
置信区间则是包含了真实参数的区间范围,一般表示为一个区间值。
在进行置信度和置信区间的估计时,需要根据具体情况选择置信水平。
置信水平是指置信区间所包含真实参数的概率,一般表示为1-α(α为显著性水平),例如95%的置信水平意味着我们有95%的把握认为真实参数落在所给定的置信区间内。常用的置信水平为90%、95%、99%等。
阐释反向传播算法
A:反向传播算法是一种常用的神经网络训练算法,用于调整神经网络中每个神经元的权重,使得网络的输出与实际值之间的误差最小化。反向传播算法通过计算误差的梯度来更新神经元的权重。
面向对象三核心
面向对象编程的三个核心概念是封装、继承和多态。
封装:将数据和方法包装成一个单独的实体,从而保证数据的安全性和可控性。对象的使用者无需知道对象的内部实现细节,只需要通过定义的接口进行访问和操作。
继承:指一个新类可以继承现有类的属性和方法,并在此基础上添加新的特征。继承可以提高代码的复用性和可扩展性,减少代码的冗余。
多态:指同一种行为具有多种不同的表现形式。在面向对象编程中,多态可以通过方法的重载和覆盖来实现。多态提高了代码的灵活性和可扩展性。
介绍一下先验概率和后验概率
先验概率指的是在考虑任何观测数据之前,对一个随机事件发生的概率有了一个先验的估计或预测。例如,对于一枚硬币来说,它是正面朝上的概率是1/2,这个概率就是先验概率,因为我们在进行任何投掷之前就已经做了这个估计。
后验概率指的是在考虑某些已知的观测数据之后,我们需要重新计算事件发生的概率。它是在贝叶斯定理的框架下被计算出来的,贝叶斯定理是基于先验概率和条件概率来计算后验概率的。
自旋锁和互斥锁的区别?
自旋锁的定义:当一个线程尝试去获取某一把锁的时候,如果这个锁此时已经被别人获取(占用),那么此线程就无法获取到这把锁,该线程将会等待,间隔一段时间后会再次尝试获取。这种采用循环加锁 -> 等待的机制被称为自旋锁(spinlock)。
A:自旋锁和互斥锁是两种常见的锁机制,它们的区别如下:
阻塞方式不同:互斥锁在资源被占用时会将线程阻塞,直到占用资源的线程释放锁,才会唤醒其他线程继续执行。而自旋锁不会将线程阻塞,而是在资源被占用时循环等待,直到占用资源的线程释放锁。
开销不同:互斥锁在资源被占用时需要进行线程上下文切换和阻塞唤醒操作,这些操作需要较大的开销。而自旋锁在资源空闲时可以快速获取锁,避免了线程上下文切换和阻塞唤醒的开销。
应用场景不同:自旋锁适用于锁占用时间较短、线程数较少的情况。因为在占用锁的时间较长、线程数较多时,循环等待会占用大量的CPU资源,从而降低系统性能。互斥锁适用于锁占用时间较长、线程数较多的情况。因为在这种情况下,上下文切换和阻塞唤醒的开销相对较小,而且可以保证线程之间的公平竞争。
介绍一下希尔排序,说说希尔排序比简单插入排序好在哪儿?
希尔排序是插入排序的一种变体。它通过比较跨越若干元素的元素来工作,因此减少了插入排序中相邻元素之间的交换次数,从而提高了算法的性能。
希尔排序的基本思想是将待排序的元素序列分成若干个子序列,对每个子序列进行插入排序,使得每个子序列都基本有序。然后再对所有子序列进行一次插入排序。
说说面向对象编程和面向过程编程有什么不同?
A:
面向对象编程和面向过程编程是两种不同的编程范式,它们有以下几点不同:
程序设计思想不同:面向对象编程是一种基于对象的程序设计思想,它将程序的组成部分看做是一个个对象,对象之间通过消息传递进行交互;而面向过程编程函数为中心进行程序设计,将程序分解成一系列的步骤,通过函数之间的调用实现功能。
抽象程度不同:OOP中的对象具有继承、封装和多态等特性,可以将具有相似属性和行为的对象进行抽象和封装,从而更好地描述问题和设计程序;POP则是通过函数调用来实现模块化的程序设计,它的抽象程度相对较低。
代码复用性不同:由于OOP中的封装、继承和多态等特性,它具有更高的代码复用性,可以通过继承来扩展已有的类或者通过组合已有的对象来构建新的对象;而POP则需要通过复制或修改代码来实现代码复用。
矩阵等价和向量组等价
等价(只有秩相同)–>合同(秩和正负惯性指数相同)–>相似(秩,正负惯性指数,特征值均相同),矩阵亲密关系的一步步深化
向量组等价:向量同维度,但个数可以不同,两者可以相互表示。
两个矩阵相似
设 A、B是两个n阶矩阵,若存在可逆矩阵P,使得 P^(-1) AP = B 则称,A相似于B,记成 A ~ B
相似具有传递性
正交矩阵、合同矩阵
正交矩阵A由一组规范正交基组成
设 A , B 为 n 阶实对称矩阵,若存在可逆矩阵 C 使得 C ^ T A C = B 则称 A与 B合同,记作 A ≃ B
什么是正定二次型、正定矩阵。
1个n*n的实矩阵 A 是正定的,当且仅当对于任意非零的实向量 x,都有 x^T A x > 0,其中 x ^ T表示 x 的转置。同样,如果矩阵 A 的所有特征值都是正数,则称 A 是正定的。
正定二次型:f(x) = x^T A x , f(x) 称为二次型,若对于任意的x,均有f(x) = xT A x >0 ,则f称为正定二次型
正定矩阵性质:
所有特征值均为正数;
对称正定矩阵的所有主子矩阵都是正定矩阵;
正定矩阵的行列式始终为正数。
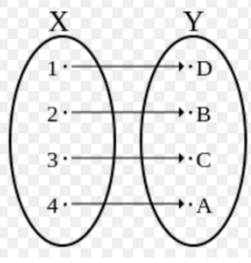
双射、满射、单射
满射:值域y是满的,每个y都有x对应,不存在某个y没有x对应的情况~
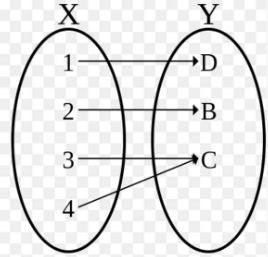
单射:没有一个x对应两个y,也没有一个y有对应两个x~
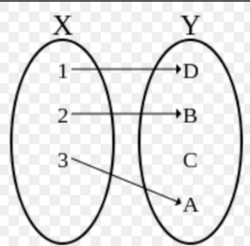
双射:每个y都有x对应,而且都是一一对应~