CNN经典模型之ALexNet、ResNet、DenseNet总结和比较
目录
ALexNet(2012
研究背景
思路和主要过程
网络模型
数据增强
主要贡献点
ResNet(2015
研究背景
思路和主要过程
Residual block(残差块)和shortcut connections(捷径连接)
bottleneck block-瓶颈模块
主要贡献点:
Denset(2017
研究背景
思路和主要过程
DenseBlock+Transitio结构
主要贡献和启发
总结与思考
ALexNet(2012
研究背景
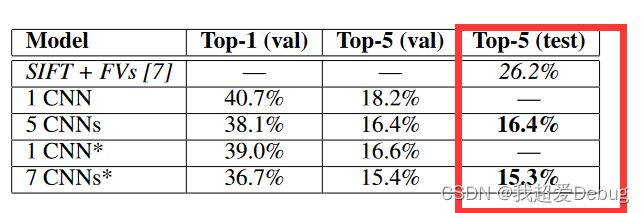
本文提出利用一个深度卷积神经网络来进行图片分类,此深度卷积神经网络(AlexNet)参加了2012年9月30日举行的ImageNet大规模视觉识别挑战赛,达到最低的15.3%的Top-5错误率,比第二名低10.8个百分点(如图1所示)。
图二左侧图是八张ILSVRC-2010测试图像和我们的模型认为最可能的五个标签。正确的标签写在每张图片下面,分配给正确标签的概率也用红色条显示(如果恰好位于前5位)。右侧图像可以理解为识别出特征向量相似的图片归类在一起

思路和主要过程
网络模型
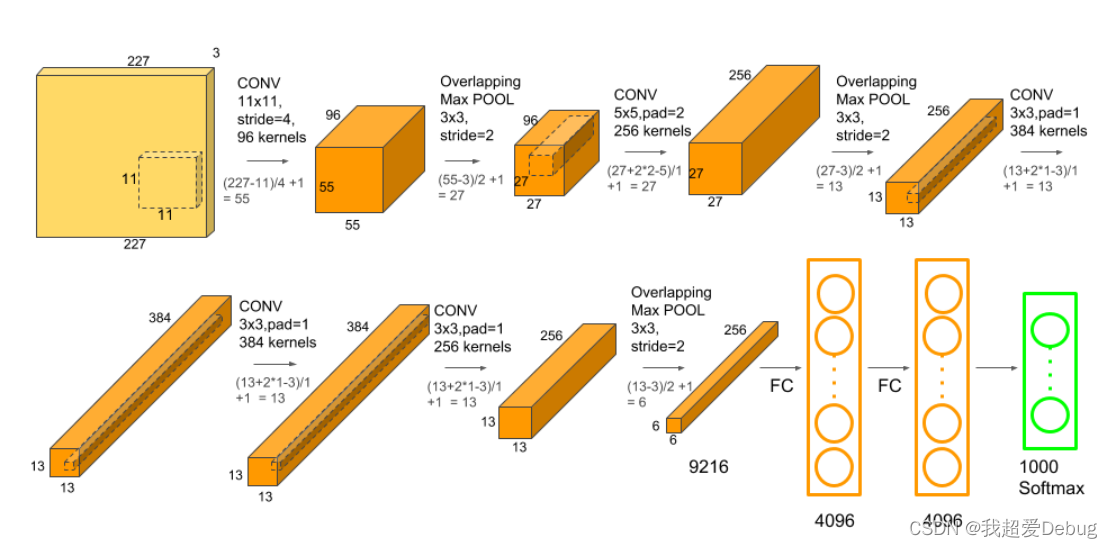
- 网络结构被一分为二成上下两部分,在两个GPU上各自训练
- 一共八层,前五层为卷积层,后三层为全连接层,最后跟的是1000路的分类激活函数softmax(来进行多元分类
- 这里可以看到卷积层只有第三层在通道维度上做了一个融合,即前一层的上下两个GPU都作为此层的输入
- 全连接层与前一层的所有神经元相连
这里可以看到我们输入的图片从一个227*227的图像变成了一个4096的语义向量,这是一个空间信息被压缩,语义信息慢慢增加的过程
数据增强
1.通过从256×256图像中随机提取224×224的图像,并在这些提取的图像上训练我们的网络来实现这一点。这将使我们的培训集的规模增加了2048倍。但是有个问题也不能说就是2048倍,因为很多图片都是相似的
2.采用PCA的方式对RGB图像的channel进行了一些改变,使图像发生了一些变化,从而扩大了数据集
主要贡献点
1.使用 ReLU 激活函数加速收敛
2.使用 GPU 并行,加速训练。也为之后的分组卷积(group convolution)理论奠定基础
3.提出局部响应归一化(Local Response Normalization, LRN)增加泛化特性(虽然被后人证明无效)
4.使用交叠池化
(Overlapping Pooling) 防止过拟合提出Dropout
5.数据增强等手段防止过拟合
ResNet(2015
研究背景
ResNet提出之前,所有的神经网络都通过卷积层和池化层的叠加组成。理论上人为,随着卷积层和池化层的层数增加时,神经网络能够获取到的图片特征信息越全,学习效果越好。但是在实际的实验中,效果却相反。造成此现象的原因有两个
- 梯度消失和梯度爆炸
- 梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0
- 梯度爆炸:若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大
- 退化问题
- 随着层数的增加,预测效果反而越来越差
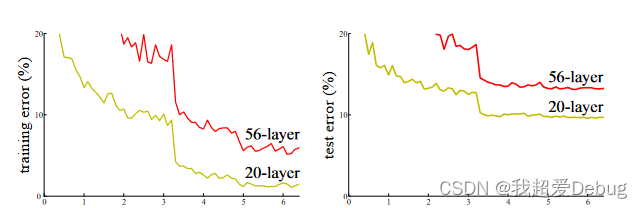
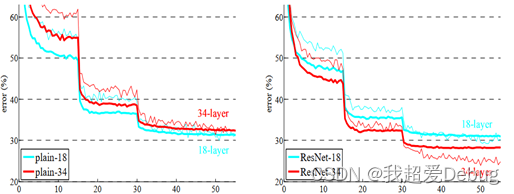
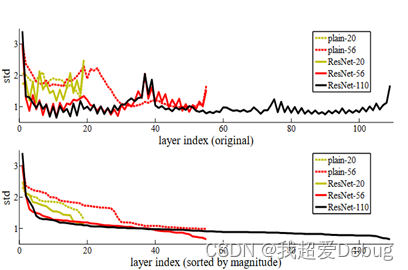
为了有效的改善退化问题,何凯明等提出了ResNet模型,效果如下图所示,随着神经网络层数的增加,有效性并没有降低,且ResNet模型斩获当年ImageNet竞赛中分类任务第一名,目标检测第一名;获得COCO数据集中目标检测第一名,图像分割第一名。
思路和主要过程
Residual block(残差块)和shortcut connections(捷径连接):
残差:
残差值F(x)=求解的映射值H(x)-估计值x
即由传统的求解每层的映射值,转换为了求映射值和估计值之间的插值,即残差值。
残差结构的优点?
1.残差结构朝着恒等映射的方向去收敛
在我们训练的一个深层的网络中,无法避免有些冗余的层(甚至是反作用的),我们期待的是,把这些层对网络的影响近似于无,对输入的结果不起变化,即这时候我们希望经过这些层的输入x和输出H(x)是近似的,即叫做恒等变换,这时候F(x)=0,这时候网络结构会随着identity mapping(恒等映射)的方向去收敛,一定程度上缓解了退化问题
2.引入残差后的映射对输出的变化更敏感
举个例子:
在引入残差之前,输入x = 6 要拟合的函数H ( x ) = 6.1
引入残差后,我们的学习目标是0.1的残差值F(x)
当接下来的层的函数值为H‘(x)=6.2的时候,相对于原来的方法,H(x)是从6.1变化到6.2,即增大1.6%,
但是对于ResNet来说,F(x)的值是由0.1变到0.2,增大到了100%
显然可见,在残差网络中输出的变化对权重的调整影响更大,也就是说反向传播的梯度值更大,训练更加容易。
shortcut connections捷径连接:
普通的卷积block与深度残差网络的最大区别在于
深度残差网络有很多旁路的支线将输入直接连到后面的层,使得后面的层可以直接学习残差,这些支路就叫shortcut
传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet 在某种程度上解决了这个问题,通过直接将输入信息绕道传到输出,保护信息的完整性,整个网络则只需要学习输入、输出差别的那一部分,简化学习目标和难度。
bottleneck block-瓶颈模块:
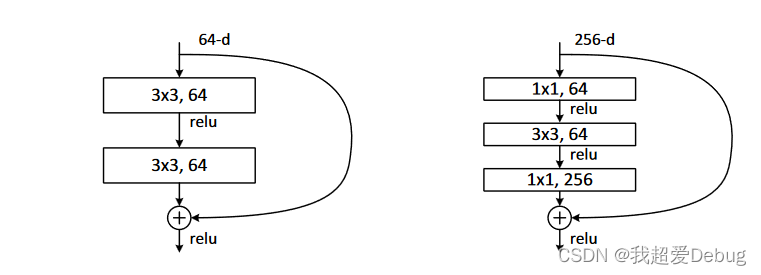
这两种结构分别针对ResNet34(左图)和ResNet50/101/152(右图),一般称整个结构为一个”building block“
”bottleneck design”,目的一目了然,就是为了降低参数的数目,第一个1x1的卷积把256维channel降到64维,然后在最后通过1x1卷积恢复,整体上用的参数数目:1x1x256x64 + 3x3x64x64 + 1x1x64x256 = 69632,而不使用bottleneck的话就是两个3x3x256的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍
主要贡献点:
既利用了深层次的神经网络又避免了梯度消散和退化的问题。
Resnet看起来很深但实际起作用的网络层数不是很深,大部分网络层都在防止模型退化,误差过大。而且残差不能完全解决梯度消失或者爆炸、网络退化的问题,只能是缓解
Denset(2017
研究背景
近期的研究表明,当当靠近输入的层和靠近输出的层之间的连接越短,卷积神经网络就可以做得更深,精度更高且可以更加有效的训练。Denset网络就是在此基础上提出来的层与层之间采用密集连接方式。
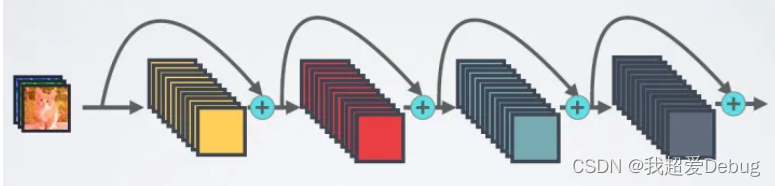
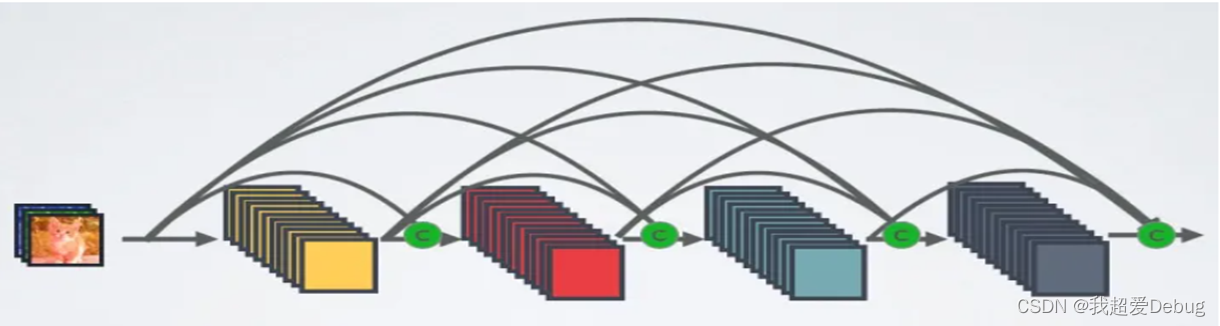
对于一个L层的网络来说,DenseNet一共包含L(L+1)/2个连接,相比于ResNet,这是一种密集连接
DenseNet是直接concat来自不同层的特征图,这可以实现特征重用,提升效率,这是DenseNet与ResNet最主要的区别
思路和主要过程
DenseBlock+Transitio结构
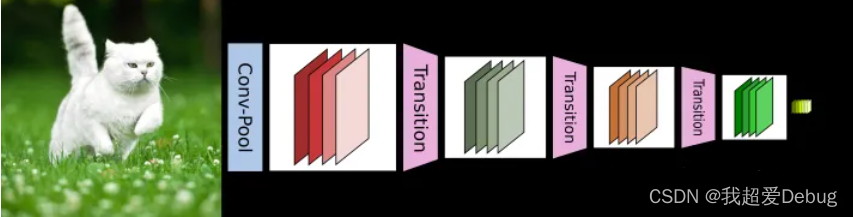
CNN网络一般要经过Pooling或者stride>1的Conv来降低特征图的大小
但是DenseNet的密集连接方式需要特征图大小保持一致,为了解决这个问题,DenseNet网络中使用DenseBlock+Transition的结构,其中DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。而Transition模块是连接两个相邻的DenseBlock,并且通过Pooling使特征图大小降低。图4给出了DenseNet的网路结构,它共包含4个DenseBlock,各个DenseBlock之间通过Transition连接在一起
主要贡献和启发
DenseNet有以下几个引人注目的优点:缓解梯度消失问题,加强特征传播,鼓励特征复用,极大的减少了参数量。
1.与传统CNNs相比参数更少,因为其不需要学习冗余特征
2.改善了整个网络中的information flow和梯度,使得训练更为容易
3.密集连接具有正则化效果,能降低训练集size较小的任务的过拟合现象
总结与思考
ALexNet是现代深度CNN的奠基之作,也是第一个深度卷积神经网络。而ResNet模型是为了解决深层次的神经网络的退化问题而提出,而残差思想本身也在一定程度上简化了模型的学习目标,使得模型训练更容易。DenseNet网络则是在ResNet的基础上,提出来的层与层的密集连接思想,并且因为实现和加强了特征重用,一定程度上减少了参数数量